![]()
![]()
Weather Prediction Using Case-Based Reasoning and Fuzzy Set Theory
by
Bjarne Kristian Hansen
A Thesis Submitted to the Faculty of Computer Science
in Partial Fulfillment of the Requirements for the Degree of
MASTER OF COMPUTER SCIENCE
Major Subject: Computer Science
APPROVED:
____________________________
Denis Riordan, Supervisor
____________________________
Mohammed El-Hawary
____________________________
Qigang Gao
DALHOUSIE UNIVERSITY - DALTECH
Halifax, Nova Scotia 2000
DALTECH LIBRARY
"AUTHORITY TO DISTRIBUTE MANUSCRIPT THESIS"
TITLE:
Weather Prediction Using Case-Based Reasoning and Fuzzy Set Theory
The above library may make available or authorize another library to make available individual photo/microfilm copies of this thesis without restrictions.
Full Name of Author: Bjarne Kristian Hansen
Signature of Author: ____________________________
Date: May 17, 2000
To Diane.
TABLE OF CONTENTS
List of Figures vii
List of Abbreviations and Symbols ix
Acknowledgments x
Abstract xi
1. Introduction 1
1.1 Hypothesis 2
1.2 Thesis structure 2
1.3 Case-based reasoning 3
1.3.1 Approaches to case-based reasoning 5
1.3.2 Challenges for case-based reasoning 7
1.3.3 Retrieval of similar cases 9
1.4 Fuzzy logic 10
1.4.1 Fuzzy logic enables retrieval of similar cases 15
1.5 Weather prediction 16
1.5.1 Airport weather prediction problem 17
1.5.2 State of the art of AI in weather prediction 21
1.5.3 Analog forecasting: An empirical weather prediction technique that depends on retrieval of similar cases 26
2. Literature Survey 42
2.1 Resources for case-based reasoning 42
2.1.1 Large databases of cases 42
2.1.2 Domain knowledge about similarity 43
2.1.3 Commercial software tools 44
2.2 Fuzzy logic and case-based reasoning 47
2.2.1 Fuzzy CBR formalism 48
2.2.2 Numerous conditions and partial matching 50
2.2.3 Flexible similarity-measuring framework 52
2.2.4 Numbers and words 54
2.3 Foundation for fuzzy k-nearest neighbors technique 55
2.3.1 k-nearest neighbors technique 55
2.3.2 Fuzzy k-nearest neighbors technique 57
2.3.3 Weather situations are not prototypical 61
2.3.4 Properties of the fuzzy k-nn technique 62
2.4 Applications that use fuzzy k-nn techniques 65
2.4.1 Weather prediction 65
2.4.2 Mergers and acquisitions 66
2.4.3 Residential property valuation 66
2.4.4 Cash flow forecasting 67
2.4.5 Shoe fashion database retrieval 68
2.4.6 Colour matching in plastics production 68
2.4.7 Criminal profiling 69
2.4.8 Identifying freshwater invertebrates 70
2.4.9 Interpreting electronic nose data 70
2.4.10 Electronics manufacturing diagnosis 71
2.5 CBR and fuzzy logic based weather prediction systems 72
2.5.1 CBR weather prediction systems 72
2.5.2 Fuzzy weather prediction systems 74
3. System for Fuzzy k-Nearest Neighbors Based Weather Prediction 77
3.1 Large database of airport weather observations 78
3.2 Fuzzy k-nn algorithm 78
3.2.1 Configure similarity-measuring function 79
3.2.2 Traverse case base to find k-nn 86
3.2.3 Make prediction based on weighted median of k-nn 89
3.3 Comparison to previous approaches 89
3.3.1 Fuzzy nearest prototype algorithm 89
3.3.2 Classic case-based reasoning 93
4. Experiments 95
4.1 Effect of varying attribute set 100
4.2 Effect of varying k 102
4.3 Effect of varying size of case base 104
4.4 Effect of varying fuzzy set membership function 106
4.5 System versus persistence 108
5. Conclusion 110
References 112
Additional References on Analog Forecasting in Meteorology 122
Appendix A: Sample Questionnaire for Knowledge Acquisition 124
Appendix B: A Worked-out Example of Fuzzy k-nn Algorithm for Prediction 128
Figure 1. Classic case-based reasoning flowchart. 4
Figure 2. CBR cycle. 5
Figure 3. Crisp sets and fuzzy sets. 13
Figure 4. Fuzzy set to describe degree of similarity of temperatures as a function of the difference between the temperatures. 15
Figure 5. Chaotic: sensitively dependent on initial conditions. 29
Figure 6. Persistence climatology (PC) bases predictions for the present case on the outcomes of similar past cases. 34
Figure 7. Crisp categories may not accurately reflect the level of similarity between cases. 35
Figure 8. Fuzzy nearest prototype algorithm. 60
Figure 9. Rule explosion in a fuzzy rule base contrasts with rule containment in a fuzzy k-nn similarity-measuring function 64
Figure 10. Twelve attributes of an airport weather observation. 78
Figure 11. Fuzzy set for comparing continuous-number attributes. 81
Figure 12. Fuzzy decision surface for comparing absolute-number attributes. 82
Figure 13. Fuzzy relationships between nominal attributes. 83
Figure 14. Fuzzy weighting for recency of attributes. 85
Figure 15. Structure of cases (i.e., weather observations). 86
Figure 16. Temporal case. 87
Figure 17. Temporal cases are compared in nested operations at three levels. 87
Figure 18. Linked list of k-nn, or weather analogs. 88
Figure 19. Cyclic algorithm for WIND-1 in pseudocode. 90
Figure 20. Similarity-measuring function: sim. 91
Figure 21. Classification based on prototypes contrasted with prediction based on nearest neighbors. 92
Figure 22. Fuzzy case-based reasoning. 93
Figure 23. Differences between classic CBR and fuzzy CBR. 94
Figure 24. Flying categories. 97
Figure 25. How outcomes of forecast and observed events are classified. 97
Figure 26. Formulae for verification of forecasts. 98
Figure 27. Attribute sets for matching. 98
Figure 28. Effect of varying attribute set. 100
Figure 29. Effect of varying k. 102
Figure 30. Effect of varying size of case base. 104
Figure 31. Effect of varying fuzzy set membership function. 106
Figure 32. Accuracy of system compared to benchmark technique, persistence. 108
Figure 33. Actual weather observations (METAR code) for Halifax International Airport. 129
Figure 34. Present case (1) and two analogs (2 and 3). 130
Figure 35. Similarity measurement between a present case (1) and two past cases (2 and 3). 131
Figure 36. Raise old low values of similarity-in effect, "forget" old dissimilarities. 133
Figure 37. Prediction based on weighted median of k-nn (k = 2). 134
List of Abbreviations and Symbols
| Abbreviation | Meaning | |
AI |
Artificial intelligence | |
CBR |
Case-based reasoning | |
DBMS |
Database management systems | |
DSS |
Decision support system | |
EC |
Environment Canada | |
FOH |
Frequency of Hits | |
FAR |
False Alarm Ratio | |
MOS |
Model output statistics (NWP + climatology + statistics) | |
MSC |
Meteorological Service of Canada (part of Environment Canada) | |
NWP |
Numerical weather prediction | |
POD |
Probability of Detection | |
TAF |
Terminal Aerodrome Forecast | |
VFR |
Visual Flight Rules | |
WIND-1 |
Weather Is Not Discrete - Version 1 | |
Symbol |
Meaning | |
m |
degree of membership in a fuzzy set, 0.0 £ m(x) £ 1.0 | |
Thanks to Diane Ouellet, my better half.
Thanks to my parents, Arthur Hansen and Elisabeth Hansen.
Thanks to all my colleagues in the Meteorological Service of Canada, part of Environment Canada, for their guidance and support during the development of this thesis. Special thanks to Jim Abraham, Bill Appleby, Réal Daigle, Allan MacAfee, Ken Macdonald, Jim Murtha, Martha McCulloch, George Parkes, Bruce Whiffen, and Laurie Wilson. Thanks to the Meteorological Service of Canada for the data and computer facilities used to conduct this research, and for paying for some of the costs.
Thanks to my supervisor Dr. Denis Riordan for showing me how case-based reasoning works and challenging me to "think about the data."
Thanks to my teacher Dr. Mo El-Hawary for showing me how fuzzy logic works and advising me to "beware of imposters in the temple" (think about the source).
Thanks to my teacher Dr. Qigang Gao for showing me how computer vision works and encouraging me to build a foundation for using computer vision with this thesis.
Thanks to Dr. David Aha for recommending relevant articles about case-based reasoning and for suggesting novel research directions.
Thanks to the University of Washington Press for letting me use two figures from The Essence of Chaos (Lorenz 1993). These figures clearly illustrate how chaotic means sensitively dependent on initial conditions . (These figures appear here in Figure 5.)
Thanks to Dr. Agnar Aamodt for letting me use a figure from Case-based reasoning: Foundational issues, methodological variations, and system approaches (Aamodt and Plaza 1994). This figure illustrates a frequently referred-to case-based reasoning cycle: retrieve, reuse, rev ise, retain (This figure appears here in Figure 2.)
A fuzzy logic based methodology for knowledge acquisition is developed and used for retrieval of temporal cases in a case-based reasoning system. The methodology is used to acquire knowledge about what salient features of continuous -vector, unique temporal cases indicate significant similarity between cases. Such knowledge is encoded in a similarity-measuring function and thereby used to retrieve k nearest neighbors (k-nn) from a large database. Predictions for the p resent case are made from a weighted median of the outcomes of analogous past cases (i.e., the k-nn, or the analog ensemble). Past cases are weighted according to their degree of similarity to the present case.
Fuzzy logic imparts to case-based reasoning the perceptiveness and case-discriminating ability of a domain expert. The fuzzy k-nn technique retrieves similar cases by emulating a domain expert who understands and interprets s imilar cases. The main contribution of fuzzy logic to case-based reasoning (CBR) is that it enables us to use common words to directly acquire domain knowledge about feature salience. This knowledge enables us to retrieve a few most similar cases from a large temporal database, which in turn helps us to avoid the problems of case adaptation and case authoring.
Such a fuzzy k-nn weather prediction system can improve the technique of persistence climatology (PC) by achieving direct, efficient, expert-like comparison of past and present weather cases. PC is an analog forecasting techn ique that is widely recognized as a formidable benchmark for short-range weather prediction. Previous PC systems have had two built-in constraints: they represented cases in terms of the memberships of their attributes in predefined categories and they r eferred to a preselected combination of attributes (i.e., cases defined and selected before receiving the precise and numerous details of present cases). The proposed fuzzy k-nn system compares past and present cases directly and precisely in term s of their numerous salient attributes. The fuzzy k-nn method is not tied to specific categories, nor is it constrained to using only a specific limited set of predictors. Such a system for making airport weather predictions will let us tap many, large, unused archives of airport weather observations, ready repositories of temporal cases. This will help to make airport weather predictions more accurate, which will make air travel safer and make airlines more profitable.
Accordingly, a fuzzy k-nn based prediction system, called WIND-1, is proposed, implemented, and tested. Its unique component is an expertly-tuned fuzzy k-nn algorithm with a temporal dimension. It is tested with the p roblem of producing 6-hour predictions of cloud ceiling and visibility at an airport, given a database of over 300,000 consecutive hourly airport weather observations (36 years of record). Its prediction accuracy is measured with standard meteorological statistics and compared to a benchmark prediction technique, persistence. In realistic simulations, WIND-1 is significantly more accurate. WIND-1 produces forecasts at the rate of about one per minute.
Fuzzy set theory based methods enable case-based reasoning (CBR) systems developers to impart the perceptiveness and case-discriminating ability of a domain expert to CBR. 1
Our goal is to develop a technique that will increase the usefulness of fuzzy methods for retrieval of similar cases. We deal with temporal cases in which the attributes are continuous variables, cases which are described by spatiotemporal vectors.
We attend to the problem of how to increase the effectiveness of a basic weather prediction technique that is referred to in meteorology as analog forecasting-a meteorological form of CBR. Analog forecasting makes predictions
for a present weather situation based on the outcomes of similar past weather situations.
Weather prediction presents special challenges for CBR. Weather is continuous, data-intensive, multidimensional, dynamic and chaotic. These five properties make weather prediction a formidable proving ground for any CBR prediction
system that depends on searching for similar sequences. Searching for similar sequences is a problem which occurs in diverse applications, such as stock market prediction (Rafiei 1999, and Xia 1997), plagiarism detection (Shivakumar and Garcia-Molina 199
5), forest fire prediction (Rougegrez 1993), and protein and DNA sequencing (Pearson and Lipman 1988). So, an effective basic technique for finding similar sequences has potentially wider applicability than for just weather prediction.
Our survey of the literature about the problem of how to determine similarity and about the nearest neighbors technique will be limited. A huge amount of such literature already exists. The problem of how to determine similarity in
terests researchers from numerous disciplines. Many papers and several books have been written on the subject of nearest neighbors techniques. 2 Most of this literature focuses narrowly on the particular discipline i
t stems from or the particular application it deals with.
We survey literature where the interests of fuzzy logic and CBR intersect (a relatively small and growing subset), and we describe in detail a unique application for weather prediction that uses a combination of fuzzy logic and CBR.<
/FONT>
Based on our previous success with weather prediction using CBR and fuzzy logic (Hansen and Riordan 1998), we hypothesize as follows:
Querying a large database of weather observations for past weather cases similar to a present case using a fuzzy k-nearest neighbors algorithm that is designed and tuned with the help of a weather forecasting expert ca
n increase the accuracy of predictions of cloud ceiling and visibility at an airport. In the rest of this chapter, we briefly introduce the three subjects of the thesis title: CBR, fuzzy logic, and weather prediction. We focus on how each subject relates to retrieval of similar cases. In Section 1.3, we explain how CBR depends on retrieval of similar cases and explain how the applicability of CBR is hindered by the problems of "case adaptation" and "case authoring." In Section 1.4, we ex
plain how fuzzy logic enables retrieval of similar cases. In section 1.5, we introduce the airport weather prediction problem addressed in this thesis, describe the state of the art of artificial intelligence in weather predicti
on, and explain how a well-known weather prediction technique known as "analog forecasting," which is a meteorological form of CBR, depends on retrieval of similar cases.
In Chapter 2, we survey the literature to focusing on how using a fuzzy k-nearest neighbors based technique for retrieval of similar cases, designed and tuned with the help of domain expert, can help us to exploit large databases of
cases and available domain knowledge about similarity, and can help us to avoid difficulties of case adaptation and case authoring. We describe the main resources for CBR, review how fuzzy logic applies to CBR, provide a foundation for the fuzzy k-neares
t neighbors (fuzzy k-nn) technique, review a number of CBR applications that exemplify the fuzzy k-nn technique, and review weather prediction papers that use CBR and fuzzy logic.
In Chapter 3, we describe our unique system for fuzzy k-nn based weather prediction. In Chapter 4, we describe a set of experiments to test the effectiveness of the system and presents the results. In Chapter 5, we present our conclusions and describe future possible directions for this research.
In this section, we give a general introduction to CBR. We condense some frequently-quoted articles about CBR. In Chapter 2, we survey articles focusing on the overl
aps of CBR, fuzzy logic, and weather prediction.
Case-based reasoning is a method for solving problems by remembering previous similar situations and reusing information and knowledge about that situation (Kolodner 1993; and Leake 1996). The original, basic idea is simple:<
/P>
A case-based reasoner solves new problems by adapting solutions that were used to solve old problems. (Riesbeck and Schank 1989) CBR is very effective in situations "where the acquisition of the case-base and the determination of the features is straightforward compared with the task of developing the reasoning mechanism." (
Cunningham and Bonzano 1999).
A classic flowchart for case-based reasoning is shown in Figure 1. The flowchart is basically the same as that of (Riesbeck and Schank 1989). We have reformatted their flowchart slightly to highlight knowl
edge-acquisition problems that continue to challenge CBR research. CBR CBR
Problem ® Input ¯ Assign Indices ¬ Indexing ¯ Rules Case Base Input + Indices ¯ Case ® Retrieve ¬ Match Memory ¯ Rules Retrieved Case Store ¯ Adapt ¬ Adaptation Assign Indices ¯ Rules Proposed Solution New ¯ Case ¬ Test ¬ New Solution ¯ ¯ Solution Failure Description Repair ¬ Repair ¯ Rules Explain ® Causal Analysis ¯ Predictive Features Figure 1. Classic case-based reasoning flowchart. This flowchart, conceptually the same as that of (Riesbeck and Schank 1989), shows how knowledge acquisition is a fundamental challenge for CBR system developers. Developers
must acquire knowledge about how to index and match cases, how to adapt cases into solutions, and how to repair failed solutions.
Based on an extensive survey of CBR, Aamodt and Plaza (1994) describe CBR as a four-step process: · Retrieve the most similar case or cases.
These steps are illustrated in Figure 2. Figure 2. CBR cycle. (Figure is copied from (Aamodt and Plaza 1994) with kind permission of Agnar Aamodt. Downloaded on November 2, 1999 from
http://www.iiia.csic.es/People/enric/AICom.html#RTFToC11) 1.3.1 Approaches to case-based reasoning
There are two basic approaches to CBR: a cognitive science based approach and a technology based approach. In the cognitive science based approach towards CBR, the goal is to explain how intelligence works. This view is expressed i
n the following statement. Real thinking has nothing to do with logic at all. Real thinking means retrieval of the right information at the right time. (Riesbeck and Schank 1989). Cognitive scientists use CBR in an effort to deconstruct thinking. To the degree that CBR imitates thought processes, CBR models thought.
Kolodner (1993) surveyed 82 CBR systems. 3 Kolodner defines a case as a contextualized piece of knowledge representing an experience that teaches a lesson fundamental to achieving the goals of the reasoner. Kolodner's definition of a case is applicable in this thesis. Kolodner describes case-based reasoning as both a cognitively plausible model of reasoning and a method for building intelligent systems. Leake (1996) identifies four elements of CBR: Case-based reasoning = retrieval + analogy + adaptation + learning According to Leake, "CBR is fundamentally analogical reasoning." Leake explains that the difference between CBR and analogy is mostly a matter of approach. Research on analogy was originally concerned with abstract knowledge and structural similarity, while research on CBR is more concerned with forming correspondences between specific episodes based on pragm
atic considerations about the usefulness of the result. Leake (1996) identifies five main problems in AI that can be improved by CBR: knowledge acquisition, knowledge maintenance, increasing problem-solving efficiency, increasing quality of solutions, and user ac
ceptance. Leake explains how CBR attempts to avoid such knowledge-related problems by assuming that there are few domain rules. Reasoning is often modeled as a process that draws conclusions by chaining together generalized rules, starting from scratch. CBR takes a very different view. In CBR, the primary knowledge source is not
generalized rules but a memory of stored cases recording specific prior episodes. In CBR, new solutions are generated not by chaining, but by retrieving the most relevant cases from memory and adapting them to fit the new situations. Thus in CBR, reason
ing is based on remembering ... remindings facilitate human reasoning in many contexts and for many tasks, ranging from children's simple reasoning to expert decision-making. Leake explains that CBR is based on the tenet that the world is regular: similar problems have similar solutions. Consequently, solutions for similar prior problems are a useful starting point for new problem-solving. For anyone building a CBR application, this begs the questions: Who's remindings are most valuable? How is the world regular? Who is most qualified to discern similarity?... Presumably, knowledgeable peo
ple, or experts.
In the technology-oriented approach towards CBR, the goal is to construct useful decision support systems, as opposed to deconstructing thought. Technology is applied science, not pure science.
Technologists build systems from whatever is useful. Problem-specific knowledge is useful for building decision support systems. Therefore, technologists use knowledge acquisition strategies to build CBR systems. Over the past ten
years, the technology-oriented approach has gained momentum. The recent "trend emphasizes the increasing importance of issues and techniques in the development of knowledge intensive CBR systems." (Aamodt and Plaza 1994).
CBR was originally proposed as an AI method to avoid the knowledge acquisition problem, the bottleneck in expert system development. CBR has been quite successful, as attested to by the reviews of Riesbeck and Schank (1989), Kolodne
r (1993), Leake (1996), and López de Mántaras and Plaza (1997). However, it has become increasingly clear in the literature that domain knowledge is valuable for technology-oriented CBR. As Aha (1998) puts it, "Knowledge engineering h
as been recast as case engineering."
1.3.2 Challenges for case-based reasoning
Knowledge acquisition is a fundamental challenge for CBR system developers. Developers must acquire knowledge about how to index and match cases, how to adapt cases into solutions, and how to repair failed solutions. Such knowledge
enables us to build the "CBR knowledge base" shown in Figure 1.
Leake (1996) identifies four challenges for CBR research: · Case adaptation: developing methods to convert imperfectly analogous cases into useful solutions.
Improving the processes of case adaptation and case authoring are probably the most significant challenges in CBR today. Both processes depend on knowledge acquisition. Leake (1996) describes the CBR challenge of case ada
ptation as follows. Central questions for adaptation are which aspects of a situation to adapt, which changes are reasonable for adapting them, and how to control the adaptation process. Answering these questions may require
considerable domain knowledge, which in turn raises the questions of how to acquire that knowledge. Many CBR systems depend on that knowledge being encoded a priori into rule-based production systems. Unfortunately, this approach raises the same
types of knowledge acquisition issues that CBR was aimed at avoiding. It has proven a serious impediment to automatic adaptation. Leake describes various methods for improving adaptation that divide into roughly two types: direct and indirect. Direct methods focus on the knowledge or methods used during adaptation. Indirect methods d
ecrease the need for adaptation by retrieving cases that require less adaptation. If neither of these methods can be made to work, then the CBR system will enter into an endless loop and fail (see loop in Figure 1).
Adaptation is a main challenge for CBR. Indirect methods for avoiding adaptation decrease the need for adaptation by retrieving cases that require less adaptation (Leake 1996). Expertise about degree of feature salience can help us
to avoid the need for adaptation. Riesbeck (1996) emphasizes that what sets CBR apart from rule-based reasoning is the presence of two processes-partial matching and adaptation- and describes the mixed status of adaptation in CBR as follows. On the one hand, adaptation is the `reasoning' part of `case-based reasoning.' Furthermore, most early CBR work focussed on the development and application of adaptation strategies, such as parameterizati
on and abstraction/respecialization (Riesbeck and Schank 1989). On the other hand, adaptation is usually the weak link in a CBR system. Adaptation techniques are hard to generalize, hard to implement, and quick to break. Furthermore adaptation is often
unnecessary. The originally retrieved case is often as useful to a human as any half-baked adaptation of it. The fuzzy k-nn algorithm performs effective partial matching with a large database, composes solutions based on a weighted median of cases (cases weighted according to their degree of similarity) and,
thereby, reduces the need for adaptation. We lessen the need for adaptation by scaling up to a large database of raw cases using a suitably designed fuzzy k-nn similarity measuring algorithm (Hansen and Riordan 1998).Case authoring is the process
of preparing cases for inclusion in a case base. Aha (1997) describes the CBR challenge of case authoring as follows. CBR is not a magic bullet for the expert systems community. It is a technology that demands attention to the process of case engineering, which bears resemblance to knowledge engineering, [and beca
use of inherent problems in case engineering] simplifying the case authoring task is of great practical value to prospective clients of commercial CBR tools. In switching from knowledge engineering to case engineering, developers trade the problem of handcrafting rules for the problem of handcrafting cases. A main problem in implementing CBR is to build the C
ase Base, as shown back in Figure 1.
The requirement for application-specific knowledge to handcraft cases creates a bottleneck in CBR development. Domain experts are prohibitively expensive to employ for the construction and maintenance of decision support systems.
1.3.3 Retrieval of similar cases
Retrieval is the first and most important process in case-based reasoning. Case-based reasoning begins with cases and cases are obtained by retrieval. The basic problem in retrieval is to find similar cases-to find good analogs.
The same problem challenges meteorologists who try to apply the technique of "analog forecasting" for the problem of weather prediction. We focus on how to improve the process of finding good analogs because the obtainment of good analogs
will reduce the need for adaptation and the dependency on case authoring.
Improving retrieval is an open problem in CBR research and CBR system development (Leake 1996). How do we select past cases that best match the present problem? Such selection depends on being able to identify and evaluate relevant
attributes and being able to perform partial matching between cases. Improving adaptation is another open problem in CBR. How do we adapt past cases that either do not agree perfectly with the current problem or do not agree with each other? Such adap
tation depends on being able to make the best possible use of imperfect analogs.
In this thesis, we propose using a variation of the fuzzy k-nearest neighbors (fuzzy k-nn) method described by Keller et al. (1985) to enable a reasoner to identify and evaluate relevant features based on the experience
of a domain expert. Experts evaluate and describe similarity fluently using a fuzzy vocabulary. For example, they might say, "Two attributes are slightly similar if the difference between their values is near 10." Eliciting suc
h knowledge from experts and encoding it in fuzzy sets enables the fuzzy k-nn method to emulate a discriminating expert at the task of finding similar cases.
Aha (1998) explains that feature weighting is the main challenge in developing k-nn algorithms. 4 He suggests that domain knowledge can assist k-nn algorithm development to weight f
eatures and to select relevant features or combinations of features. This thesis explains how a fuzzy k-nn technique helps us to obtain and use such knowledge about feature salience for determination of similarity. According to Luger and Stubblef
ield (1998): One of the most subtle and critical issues raised by CBR is the question of defining similarity. Although the notion that similarity is a function of the number of features that two cases have in common i
s quite reasonable, it masks a number of profound subtleties. For example, most objects and situations have an infinite number of potential descriptive properties; case-based reasoners typically select cases on the basis of a tiny retrieval vocabulary.
Typically, case-based reasoners require that the knowledge engineer define an appropriate vocabulary of highly relevant features. Although there has been work on enabling a reasoner to determine relevant features from its own experience, determining rele
vance remains a difficult problem. The fuzzy k-nn system queries a database using whichever potential descriptive properties best fit the present situation. The fuzzy k-nn system, rather than learning about important similariti
es and determining relevance "from its own experience," is taught opportunistically by a domain expert who is already well experienced at comparing attributes of cases and able to fluently describe important similarities with fuzzy words.
In the previous section, we explained how CBR depends on retrieval of similar cases. In this section, we give a general introduction to fuzzy logic and explain how it can be used to achieve retrieval of similar cases. We do not dea
l with fuzzy logic in depth-many books and articles have done this already. All the fuzzy logic methods used in this thesis are explained in detail by Zimmerman (1991).
Fuzzy logic is an established methodology that is widely used to model systems in which variables are continuous, imprecise, or ambiguous. 5 The main idea of fuzzy logic is that items in the real
world are better described by having partial membership in complementary sets than by having complete membership in exclusive sets. 6 This has the effect of increasing the resolution and the fidelity of categorizatio
n.
For example, suppose we can assign people into two sets, short and tall. In classical logic (i.e., non-fuzzy or "crisp" logic) an arbitrary threshold is specified. For instance, someone who is shorter than 1
60 cm is deemed to be short, and someone who is 160 cm or taller is deemed to be tall. Using this logic, one would conclude that two people who are of nearly identical height, 159 cm and 160 cm, fall into opposite categories of height, one
short and the other tall. This is not how people think.
Whereas, in using fuzzy logic, an item may have partial membership in two or more sets. Someone who is 160 cm can have 0.5 degree membership in the short set and 0.5 degree membership in the tall set. For different he
ights, memberships can range continuously from 0.0 to 1.0 to accord with human perception. Fuzzy logic models how people think.
A fuzzy logic based methodology is used in this thesis for the following reasons. · Fuzzy logic is effective for eliciting and encoding knowledge from domain experts (Kantrowitz et al. 1997). For instance, such knowledge can control recog
nition of similarity between two weather situations (Hansen 1997).
Zadeh (1999) explains the third point in an article entitled From computing with numbers to computing with words-from manipulation of measurements to manipulation of perceptions. Zadeh's vision is an inspiration for
the fuzzy k-nearest neighbors technique described in this thesis. Zadeh (1996) expresses optimism for fuzzy logic partnering with other techniques, such as machine learning theory and chaotic systems analysis, both of which are touched on in this
thesis.
Fuzzy logic is especially useful for CBR because: CBR is fundamentally analogical reasoning (Leake 1996), analogical reasoning can operate with linguistic expressions, and fuzzy logic is designed to operate
with linguistic expressions.
Fuzzy logic operates with linguistic, realistic variables, whereas classical logic operates with Boolean, discrete variables. A database query example illustrates the difference between the two. Suppose a marketing business is inte
rested in identifying employees who have high potential. It could search its employee database for all employees who are young and who have high sales. Two approaches to querying the database are crisp range based and fuzzy set based.
The crisp approach is depicted in Figure 3 (a) (b) and (c). With the crisp approach, one specifies a discrete range based query as follows:
young
Û age
£
25 years high sales
Û sales
³
$500,000 per year If there is an employee who is 26 years old who averages $1 million per year in sales, the crisp search would fail to identify this employee. This employee has "zero membership" in the overlap of the specified crisp sets.
Yet, most people would reasonably think that this person is young and has high sales.
The fuzzy approach is depicted in Figure 3 (d) (e) and (f). With the fuzzy approach, one specifies a fuzzy set based query, in which fuzzy sets determine degree of membership in the sets young and <
I>high sales. Figure 3. Crisp sets and fuzzy sets. Functions for dual membership in two sets. Arrows show how a 26-year old million-dollar-selling employee is accorded different levels of membership in the set young with high sales by crisp sets and by fuzzy sets. Using crisp sets, membership equals zero, whereas using fuzzy sets membership equals 0.9. The latter membership is more consistent with how people think.
The dual membership in the sets of those young with high sales for the 26-year-old, million-dollar-selling employee is calculated as follows. max{
myoung,
mhigh sales} = max{0.9, 1.0} = 0.9 The employee has 0.9 degree of membership in the specified fuzzy sets. This is consistent with the view that most people would have that this person is young and has high sales. Knowledge of how to interpr
et and evaluate such attributes can be obtained by interviewing an expert and encoding their responses as fuzzy sets.
Srinivasan et al. (1994) describe four enhancements that fuzzy logic provides to a neural network, which could also be provided to CBR, as follows. · "Amalgamation of different pieces of knowledge is possible by application of fuzzy rules."
For instance, point number 4 implies, for CBR, that we could avoid the need to re-optimize the entire case-comparison weight vector every time a new predictive/selective piece of knowledge is added to a similarity measuring
function.
Elicitation of domain knowledge is a basic and common application of fuzzy logic. The "Fuzzy Logic FAQ" explains how membership values can be determined through subjective evaluation and elicitation as follows. As fuzzy sets are usually intended to model people's cognitive states, they can be determined from either simple or sophisticated elicitation procedures. At the very least, subjects simply draw or otherwi
se specify different membership curves appropriate to a given problem. These subjects are typically experts in the problem area. Or they are given a more constrained set of possible curves from which they choose. Under more complex methods, users can b
e tested using psychological methods. (Downloaded on April 20, 2000 from
http://www.cs.cmu.edu/Groups/AI/html/faqs/ai/fuzzy/part1/faq.html) Fuzzy methods represent cases with any combination of words and numbers. The fuzzy k-nn technique retrieves similar cases by emulating a domain expert who understands and interprets similar cases. T
he main contribution of fuzzy logic to case-based reasoning (CBR) is that it enables us to use common words to directly acquire domain knowledge about feature salience. This knowledge enables us to retrieve a few most similar cases from a large database,
which in turn helps us to avoid the problems of case adaptation and case authoring. When cases don't fit perfectly, as often they never will, a practical option may be to inspect many cases, select the few most similar cases, and make reasonable inferen
ces.
1.4.1 Fuzzy logic enables retrieval of similar cases
When domain experts are presented with a set of three unique situations and asked to describe the similarity between the three pairs in the set, they are more likely to say "very, somewhat, and slightly" than to say "y
es, no, and I don't know." The former response couches the description of similarity in uncertain words, or fuzzy words. The inherent uncertainty is due to fuzziness, not randomness.
Figure 4 shows how such words map to fuzzy sets and thereby enable fuzzy operations to emulate a domain expert in the task of comparison. For a simple example, consider the problem of describing the similar
ity of three weather situations where, for simplicity of illustration, each weather situation is described only by temperature. The fuzzy set shown in Figure 4 solves this problem. Figure 4. Fuzzy set to describe degree of similarity of temperatures as a function of the difference between the temperatures. Fuzzy set models cognitive state of expert weather forecaster who evaluates differences.
Fuzzy set emulates expert at comparison.
The fuzzy set in Figure 4 is designed by interviewing an expert weather forecaster who is familiar with local effects. We ask the expert, "At what points do you consider two temperatures to be slightly
similar, quite similar, and very similar?" The above fuzzy set maps a response of "8_C, 4_C, and 2_C." The function is unimodal, continuous, and returns values in the range (0.0...1.0]. Fuzzy sets such as this are the basic component of
the fuzzy k-nn technique.
Such fuzzy sets are a form of acquired knowledge. This is knowledge about relevance, feature salience, and importantly similar attributes. This is not knowledge in the form of rules, which is the commonest AI sense of knowledge.
Fuzzy sets allow a function, m(x), to measure similarity between any attributes in the way that an expert would. For example:
humidity difference of 5% ® very similar ® m(5) = 0.75 humidity difference of 20% ® slightly similar ® m(20) = 0.25 In comparing cases composed of multiple attributes, attributes that are more important than others have narrower fuzzy sets. For example, wind direction affects local weather more strongly than temperature, so it should have a narro
wer, more discriminating fuzzy set.
A system equipped with such a similarity-measuring function can take the present temporal case and rate all the previous cases in terms of similarity. In practice, all cases have similarity scores: 0.0 < sim < 1.0 This
quality of the fuzzy k-nn technique reflects perception of real weather cases, which is that real weather cases are never identical and are never "totally dissimilar." We combine fuzzy logic with CBR because fuzzy logic is helpful for acquiring knowledge and it provides methods for applying knowledge to real-world data. Fuzzy logic simplifies elicitation of knowledge from
domain experts, such as knowledge of how similarity between two cases depends on the difference between their individual, collective, and temporal attributes. Fuzzy logic emulates human reasoning about similarity of real-world cases, which are fuzzy, th
at is, continuous and not discrete. For example, using fuzzy sets elicited from a weather forecaster who is experienced at comparing and evaluating similarity between weather cases, fuzzy logic emulates the forecaster at the task
of recognizing good analogs. In the previous two sections, we introduced CBR and fuzzy logic and explained how these subjects relate to retrieval of similar cases. In this section, we briefly introduce weather prediction, describe a method of weather prediction
called "analog forecasting" (a meteorological form of CBR), and explain how analog forecasting depends on retrieval of similar cases.
Fundamentally, there are only two methods to predict weather: the empirical approach and the dynamical approach (Lorenz 1969a). The empirical approach is based upon the occurrence of analogs (i.e., similar weather situations). The
dynamical approach is based upon equations of the atmosphere and is commonly referred to as computer modeling. The empirical approach is useful for predicting local-scale weather if recorded cases are plentiful (e.g., cloud ceiling and visibility in a fe
w square kilometres around an airport). Because of grid coarseness, the dynamical approach is only useful for modeling large-scale weather phenomena (e.g., general wind direction over a few thousand square kilometers).
Weather prediction is regarded by meteorologists as both a science and an art. Weather prediction relies upon objective techniques based upon decades of research, and it relies upon subjectivity and judgment based upon personal expe
rience and local rules and practices. We will regard weather prediction as an objective process. Objective techniques are universal, whereas subjective techniques are local. Objective techniques are used consistently and are portable, whereas subjectiv
e techniques are used inconsistently: subjective techniques vary from person to person, from time to time, and from place to place. Analog forecasting is an objective method for weather prediction that makes predictions for a present weather situation ba
sed on the outcomes of similar past weather situations. Analog forecasting is the weather prediction technique that we aim to improve.
In subsection 1.5.1, we introduce the airport weather prediction problem addressed in this thesis. In subsection 1.5.2, describe the state of the art of artificial intelligence in
weather prediction. In subsection 1.5.3, we describe the analog forecasting technique and explain how it depends on retrieval of similar cases.
1.5.1 Airport weather prediction problem
An airport weather prediction is a concise statement of the expected meteorological conditions at an airport during a specified period (US National Weather Service Aviation Weather Center, 1999). An airport weather prediction is, in
meteorology, commonly referred to as TAF, short for Terminal Aerodrome Forecast. When pilots give weather forecasts to passengers before landing, they are reading TAFs.
TAFs are made by expert forecasters. These experts have general knowledge about how large scale weather systems behave and specific knowledge about how local scale weather phenomena behave idiosyncratically at specific airports. Ex
perts bridge the gap between simple persistence forecasting and NWP-assisted statistical forecasting on the local scale (Battan 1984).
The three types of forecasts most commonly made by forecasters are TAFs, public forecasts and marine forecasts. Of these, TAFs are the most precise and thus the most challenging type of forecast to make, both in terms of measurable
weather conditions and in terms of timing. Forecasts of the height of low cloud ceiling are expected to be accurate to within 100 feet. Forecasts of the horizontal visibility on the ground, when there is dense obstruction to visibility, such as fog or s
now, are expected to be accurate to within 400 metres. Forecasts of the time of change from one flying category to another are expected to be accurate to within one hour. In comparison, public and marine forecasts can be much less precise. For example,
in public forecasts, it may be sufficient to predict "variable cloudiness this morning," and in marine forecasts, it may be sufficient to predict "fog patches forming this afternoon."
NAV CANADA 7 measures TAF performance in four ways, with three ceiling and visibility accuracy statistics 8 and with a speed-of-amendment statistic. The commo
nest cause for amendments is unforecast ceiling or visibility (Stanski 1999). So, accurate predictions of cloud ceiling and visibility are clearly important.
In this thesis, we are only directly concerned with the two qualities of TAFs that are routinely measured by NAV CANADA, which are as follows. · Accuracy of prediction of flying condition category. Flying category determined by both cloud ceiling height and horizontal visibility, two obstructions to vision for pilots. The lower the forecast categor
y, the more expensive precautions pilots must take.
So, to improve the quality of airport weather predictions, the three main challenges are: 1.5.1.1 Motivations for improving airport weather prediction
The motivations for improving the airport weather prediction process are both ergonomic and economic. Airport weather forecasting is a difficult task for forecasters. A system that can provide forecasters with improved and timely g
uidance will help to make their work easier and thus help to make them more effective.
TAFs are economically important to TAF users, providers, and producers. Airlines use TAFs. In Canada, NAV CANADA provides TAFs to airlines and Environment Canada (EC) produces TAFs for NAV CANADA.
Accurate TAFs increase the safety of airplane passengers and the profitability of airlines. When "bad weather" 9 is forecast at the destination airport of an airplane, the pilot must lo
ad on extra fuel to ensure the airplane will be able to reach an "alternate airport" in case diversion en route becomes necessary. So, reliable forecasts of airport weather-"bad weather" and "good weather," at destinations
and alternates-are important for the safety of airplane passengers.
At the same time, airlines do not want airplanes to carry more fuel than necessary for safety. It is expensive to fly fuel from one airport to another. Unused fuel on arrival is an unwanted expense. As TAF accuracy increases, the
benefit to airlines increases. Leigh (1995) studied the of effect of TAF accuracy and concluded that "the economic benefit of a uniform, hypothetical increase in TAF accuracy of 1% is approximately $1.2 million [Australian] per year for Qantas inter
national flights into Sydney."
Patton (1996) interviewed airplane pilots to determine how they behave in response to government transportation regulations, airline policies, air traffic flow management, types of airplanes, and airport weather forecasts. Pilot beh
avior is complex to say the least 10, but it is clear from her investigation that inaccurate, pessimistic airport forecasts cause pilots to load on extra "unnecessary" fuel and that this directly increases op
erating costs for airlines.
Thirteen years ago, White (1987) reported that then-recent improvements in forecasts had enabled airlines served by the U.K. Meteorological Office to significantly reduce fuel consumption and thereby save an estimated £50 milli
on per year.
There is a growing market for more accurate and more up-to-the-minute TAFs. White (1995), a director of the International Air Transport Association (IATA), identifies important economy-driven and computer-assisted trends in the avia
tion industry. The aviation industry contributes about $1 trillion [US] per year to the global economy and air travel is growing at a rate of about 6% per year. By equipping airplanes with the "latest space-age technology options to optimize perfor
mance," the IATA has the goal of establishing "an era of `free flight,' meaning a kind of Utopian environment where aircraft can operate on a totally flexible `flight plan' making optimum use of prevailing weather conditions and forecast updates
. ATC [Air Traffic Control] will only intervene when necessary to prevent serious loss of separation."
In Canada alone, the production of TAF's accounts for about $5,000,000 a year revenue to Environment Canada (EC). 11 EC is contracted to provide accurate and timely predictions of ceiling and vis
ibility to NAV CANADA. A system which could provide useful ceiling and visibility guidance to make TAF's, autonomously and using real-time data, would be helpful for EC. EC, like all public and private sector agencies, is under continuous pressure to ec
onomize (Doswell and Brooks 1998). TAFs are expensive to produce, presently costing about $30,000 per year per airport for round-the-clock coverage (Macdonald 1998).
TAFs are a good value for airlines. To estimate their value, Doyle (1995) developed a plausible scenario, incorporating several reasonable assumptions, in which forecast service for a set of airports is withdrawn, and calculated wha
t the resultant extra costs would be to Air Canada. Extra costs would result because pilots, when filing flight plans, could not use the affected airports as "alternate" landing sites, and would therefore have to file more distant airports as a
lternate, and would therefore have to load on and fly more fuel, which is expensive to do. In the scenario, forecast service is withdrawn from nine airports and the estimated resultant extra costs to Air Canada are $450,000 per year. The scenario does n
ot take into account potential savings from not having to pay for TAF production costs of $270,000 per year (= 9 × $30,000). But even assuming TAF production costs could be subtracted from additional fuel-carrying costs, Air Canada would still lose
$270,000 per year in the scenario.
The scenario of (Doyle 1995) only accounted for additional fuel-carry costs to airlines resulting from removal of TAF coverage for alternate airports. There would certainly be two other additional costs: · Diversions to remoter alternate airports would cause additional costs to airlines, such as lodging, transporting, and placating dissatisfied passengers.
1.5.2 State of the art of AI in weather prediction
The state of the art of AI in weather prediction is advancing steadily. Recently, Christopherson (1998) surveyed the meteorology literature and identified over 40 AI-meteorology papers, whereas ten years ago a similar survey by Conw
ay (1989) identified only 4 such papers.12 Operational forecast systems using AI are now being used by the Meteorological Service of Canada (MSC), the U.S. Army, and the U.S. Navy (Christopherson 1998). In 1998, the
American Meteorological Society gave its "stamp of approval" to AI by holding its First Conference on Artificial Intelligence.
Conway (1989) identified three special challenges which meteorology places on AI: 13 · Need for convenience and speed.
Fuzzy techniques can assist in all of these challenges. Forecasters do not stop reasoning when they miss certain data, or have conflicting or ambiguous data; they continue to reason and attach an appropriate level of uncer
tainty to their conclusions. Conway (1989) explains how forecasters reason with inconclusive data as follows. As humans we do not normally reason in numerical terms but prefer vaguer notions of things being `probable' or `likely,' so the appropriate assignment of probabilities is one of the main difficulties of en
coding human expertise in the form of rules. How best to deal with `reasoning under uncertainty' is a subject of continuing research in the expert systems community. Instead of trying to assign appropriate probabilities or to encode expertise in rules, which are difficult tasks, the fuzzy k-nn technique uses the following "vaguer notions." · Similar weather situations (cases) evolve similarly.
The driving force behind the development of AI-meteorology systems is the need to deal more effectively with the immense stream of data that forecasting depends upon. For example, we receive about 10 Megabytes per second o
f remotely sensed data from satellites. 14 NWP also produces huge amounts of data which needs to be incorporated together with other types of predictive information into forecasts. Weather forecasters need improved c
omputer systems and AI systems to take better advantage of huge and ever-increasing amounts of data.
Klein (Dyer and Moninger 1988) identifies two problems facing developers of expert systems for weather prediction. First, the "genuine expert" may be difficult to find or identify (e.g., two alleged experts may contradict
each other). Second, "there are pitfalls inherent in the practice of asking the expert to describe the unusual or difficult cases to the exclusion of ordinary events." Uncommon situations may be over-represented by the inference engine. This
would emulate the occasional tendency of weather forecasters to "over-forecast weather." 15 Asking a forecaster to describe all the difficult situations may lead to an unnecessarily complicated view of the f
orecasting process. CBR, or the fuzzy k-nn technique, can help us to avoid both problems, first, by reducing dependency on an expert and on knowledge acquisition, and, second, by giving all past cases an equal chance to affect the prediction for t
he present case.
Meyer (Frankel et al. 1995) suggests that "AI might have a role in assisting the forecaster in interpreting the output of numerical models [NWP] and adjusting it for local conditions." Mosher (1998) claims that, "Even
with the new mesoscale forecast models, the meteorological forecaster can add value to the [NWP] guidance. The forecaster can provide unique information that is not available from [NWP]." Similarly, AI can combine unique data from complementary so
urces, such as airport weather archives and NWP. Fuzzy logic and the fuzzy k-nn technique are well-suited to combining and operating on heterogeneous types of data. 16
Christopherson (1998) expresses optimism for the future of AI in meteorology when he concludes his survey as follows. The complexity of the modern weather forecasting (more datasets, modern information processing systems, larger areas of forecasting responsibility, shorter deadlines, more detailed forecasts), has many att
ributes which are defined for the application of AI. ... Forecasters need assistance to more fully utilize this "data flood" and develop the modern forecasting process. AI techniques, particularly expert systems and neural networks, offer solu
tions to these problems. Christopherson (1998) qualifies his optimism by describing hurdles for AI acceptance and use in weather forecasting as follows.
1.5.2.1 Why meteorologists have rarely used artificial intelligence
Based on extensive consultation with forecaster-developers and meteorological researchers working in AI development, and on a survey of over 40 AI-meteorology systems, Christopherson (1998) lists probable causes for the limited accep
tance and use of AI in operational forecast offices as follows. 1. "The lack of specific, national level plans to integrate such technologies into the forecast process."
Considering points number 3 and 4 together helps to explain why, in meteorological research, interest in the development of the analog forecasting technique has been almost completely displaced by interest in computer model
ing (NWP). Over the past 30 years, NWP has come to dominate many meteorological research agendas. 17 At the same time, little innovation has been attempted with analog forecasting techniques. All of the references t
o analog forecasting in the meteorological literature of the past 30 years rely heavily on statistical techniques, techniques that have hardly changed over the past 30 years. 18
1.5.2.2 Why meteorologists need decision support systems
By interviewing forecasters, Kumar et al. (1994) found four reasons why forecasters need decision support systems, which are paraphrased as follows. · Forecasters are challenged in their present work setting to absorb, comprehend, and remember a large amount of information which arrives in a continuous stream. Tight deadlines exacerbate
the problem. As a result, forecasters sometimes make "errors in judgment."
Kumar et al. (1994) used the machine learning technique of inductive learning to obtain prediction rules. These prediction rules were the basis of a system to predict 24-hour rainfall in Melbourne City, Australia. Their p
roblem was to make categorical predictions of rainfall during a 24-hour period in Melbourne City Australia. They had a 30-year set. They used up to 129 attributes. Of these attributes, 59 were from NWP prognostic fields. So, they combined clima
tological and NWP guidance. They used inductive learning programs to build decision trees. 19 The output of the learning programs was represented as sets of rules and forecasters were asked to comment on these rules.
According to the forecasters, even though the induction methods performed slightly better than the current prediction method, it is much easier for the forecasters to understand and use the automatically g
enerated symbolic production rules by the induction method than the current complex statistical method, to perform the forecasting operations. 20 Compared to statistical methods, machine learning has a good explanation capability, a desired quality in AI systems. It promotes user acceptance. Given a choice, users seem to prefer "transpar
ent systems" over "black boxes"-scrutability over inscrutability. The fuzzy k-nn method should appeal to users in the same way. Its solutions are composed from actual cases-cases which can be presented to users to scrutinize if the
y so desire.
1.5.3 Analog forecasting: An empirical weather prediction technique that depends on retrieval of similar cases
Weather patterns repeat themselves-this is the basic idea behind the weather prediction technique called analog forecasting. Analog forecasting is a meteorological form of CBR. Analog forecasting is simple in theory: make
a prediction for the current situation based on the outcome of similar past situations. However, development of analog forecasting systems is challenging in practice.
Analog forecasting is by far the oldest weather prediction technique. Useful weather sayings are based on recurring patterns of weather, and using recurring patterns of weather is essentially analog forecasting, thus useful weather
sayings are a form of analog forecasting. For example, the following familiar saying is at least 2000 years old. 21 Red sky in the morning, sailors take warning. The Online Guide to Weather Forecasting 22 describes analog forecasting as follows. It involves examining today's forecast scenario and remembering a day in the past when the weather scenario looked very similar (an analog). The forecaster would predict that the weather in this forecast
will behave the same as it did in the past. ... The analog method is difficult to use because it is virtually impossible to find a perfect analog. Various weather features rarely align themselves in the same locations they were in the previous time. Ev
en small differences between the current time and the analog can lead to very different results. However, as time passes and more weather data is archived, the chances of finding a `good match' analog for the current weather situation should improve, and
so should analog forecasts. In a practical sense, the fuzzy k-nn method learns as cases accumulate. As databases of cases increase in size, the chance of finding good analogs for any given weather situa
tion increases.
To use analog forecasting, we must find good analogs and we must use these analogs appropriately. The two main challenges are: · Develop a good similarity metric. · Determine confidence intervals and practical time scales for analog predictions. 1.5.3.1 Investigations into feasibility of analog forecasting uncovered chaos
The work of Edward Lorenz is seminal in the modern "science of chaos." In the past, chaotic commonly meant disorder, uncertainty or randomness. Increasingly, chaotic describes a special type of order observe
d in systems in real-world areas such as physics, economics, statistics, chemistry, engineering, biology, and medicine (Abarbanel et al. 1993).
Lorenz (1963, 1969b, 1977, and 1993) tested the feasibility of using models, based on either analog forecasting or on physical equations of the atmosphere, to produce long-range weather forecasts. Lorenz reasoned that because weathe
r obeys deterministic physical laws, if one could initialize a weather model perfectly, then deterministic long-range weather forecasting would be possible. He noticed that tiny errors in model initializations grow exponentially into large errors as mode
ls run forward in time. In the real world, such errors are inevitable because of practical limitations on weather measurement precision and accuracy. Model initialization errors limit the time range of both analog forecasting systems and numerical weath
er prediction systems. Lorenz (1963) concluded that the results of his experiments indicated that: prediction of the sufficiently distant future is impossible by any method, unless the present conditions are known exactly. In view of the inevitable inaccuracy and incompleteness of weather observations,
precise very-long-range forecasting would seem to be non-existent. Lorenz explained what his results implied for the feasibility of long-range analog forecasting: long-range, global weather prediction is infeasible because the atmosphere is sensitively dependent on initial
conditions. 23 For deterministic weather prediction to be possible, one would have to find a perfect analog for the present case. However, because the global atmosphere exists in innumerable states, there are
two impediments for analog forecasting. First, it is highly unlikely that perfect analogs ever exist. 24 Second, even if perfect analogs did exist, it is technically impossible to measure the atmosphere to the requir
ed level of precision. Lorenz (1963) noted that "these conclusions do not depend upon whether or not the atmosphere is deterministic." Today, Lorenz' conclusions are accepted in meteorology.
Reflecting on over three decades of research, Lorenz (1993) concludes, "We are left with the strong impression that the atmosphere is chaotic, but we would like additional evidence." We assume that weather is chaotic and t
hat it behaves accordingly, that is, that the flow of weather is sensitively dependent on initial conditions.
1.5.3.2 Temporal cases are chaotic trajectories
A temporal case is a short segment of a long record of a multidimensional, real-world process. In this thesis, and in general, a temporal case can describe any recorded, real-world process. In theory, if tw
o distinct temporal cases are identical, then the sequences of events following those two cases will be identical. If one of those cases describes the present situation, then the problem of prediction is deterministic-one simply predicts a recurrence of
the sequence of events that followed the previous identical case. However, in reality, identical cases are usually rare and case-based prediction is seldom so simple. There are fundamental practical limitations on case-based prediction method. These li
mitations are described in this section. These limitations will be reiterated in subsection 2.2.1 (pg. 48) when we review a fuzzy logic based formalism for deterministic CB
R, proposed by Dubois et al. (1997), that is based on the principle: "The more similar are the problem description attributes, the more similar are the outcome attributes."
In weather prediction, the method closest to CBR is analog forecasting. Analog forecasting is based on the principle that the more similar the current weather situation is to a past weather situation, the more similar the upcoming w
eather will be to that which followed the past weather situation. In its strongest form, this principle implies deterministic weather prediction.
In the real-world, chaos prevents determinism. Chaos imposes fundamental limitations on the applicability of case-based reasoning for predicting physical processes. Small differences between the initial states of two systems tend t
o grow exponentially over time and the two systems become increasingly dissimilar.
A good way to appreciate chaos, and the implications of a system being sensitively dependent on initial conditions, is with the following demonstration by Lorenz (1993). Suppose a snowboard starts sliding down a bumpy ski slope from
a certain position at a certain velocity. The snowboard slides freely down the slope, curving left and right as it swerves away from bumps on the slope. A number of such trajectories are illustrated in Figure 5. Each such tra
jectory is a specific temporal case. (a) Initial displacements
(b) Initial displacements
Figure 5. Chaotic: sensitively dependent on initial conditions. Each figure shows the paths of seven snowboards crossing a starting line with varying initial displacements and identical velocities. Diamonds in Figure 5 (a) indicate centers of bumps in snow. (Figures are copied from (Lorenz 1993) with kind permission of the University of Washington Press.)
The effects of varying initial conditions on the trajectory was tested by Lorenz with computer simulations. Each snowboard began on the starting line with the same velocity, both forwards and sideways components. The only condition
made to vary was x, the position of the snowboard on the starting line. In the first set of trials, initial displacements were incremented by 10 cm, as shown in Figure 5 (a). In the second set of trials, initial displac
ements were incremented by only 1 mm, as shown in Figure 5 (b).
The results clearly show how the trajectory is sensitively dependent on initial conditions. The more similar the initial conditions of two temporal cases are, the more similar the outcomes are. Given the initial coordinates
of a ski on the slope and a case base of past complete trajectories, it is possible to predict the path of the ski using an analog forecasting method: Make predictions based on the outcomes of similar past situations.
The snowboard analogy shows how analog forecasting works and how it fails. Differences between the states of two systems, which are initially similar, tend to grow exponentially over time. This implies that there is a practical lim
it on the time range of analog forecasting. Comparing Figure 5 (a) with Figure 5 (b), note that even though the initial conditions in (b) are 100 times closer than in (a), the tracks in (b) remain simil
ar for only about twice the distance as in (a). The tracks in (a) diverge sharply after about 20 metres and the tracks in (b) diverge sharply after about 40 metres. Small initial differences tend to grow exponentially over time. So, in a chaotic enviro
nment, any attempt to improve analog forecasting by using increasingly similar cases will yield diminishing returns.
Confidence in the predictions depends on the distribution of the analogs. So long as the analogs are packed together, the predictions are precise and reliable. After the analogs fan apart, the predictions are vague and unreliable.<
/FONT>
To use an analog forecasting method appropriately, the main limitation to recognize is the practical time range. We must identify the point in time when analogs become so dissimilar from each other th
at analog forecasts become unreliable. In meteorology, this concept is referred to as a "limit of predictability."
1.5.3.3 State of the art of chaotic data analysis
This subsection simply highlights some observations made by Abarbanel et al. (1993) in a review entitled The analysis of observed chaotic data in physical systems. These observations are both motivational and instructive for
this thesis. · "In a sense we shall describe new methods for the analysis of time series, but on another level, we shall be providing handles for the investigation and exploitation of aspects of p
hysical processes that could simply be dismissed as `stochastic' or random when seen with different tools. Indeed the view we take in this review is that chaos is not an aspect of physical systems to be located and discarded, but is an attribute of physi
cal behavior that is quite common and whose utilization for science and technology is just beginning. The tools we discuss here are likely also to be just the beginning of what we can hope to bring to bear in the understating and use of this remarkable f
eature of physical dynamics."
We intend to put "good physics" into the analog forecasting method by equipping fuzzy sets to measure importantly close physical dimensions.
To implement an analog forecasting method, the main problem to solve is to find good analogs. Somehow we must select past cases whose attributes are most similar to those of a new, partial, and (in th
e case of complex natural phenomena, such as weather) probably unique case.
1.5.3.4 Persistence climatology: Analog forecasting with built-in constraints
"Persistence climatology is widely recognized as a formidable benchmark for very short range prediction of ceiling and visibility [which are critical attributes of airport weather]" (Vislocky and Fritsch 1997).
Persistence climatology (PC) is a weather prediction technique that combines the best qualities of two basic weather prediction techniques: persistence forecasting and climatological forecasting. PC is a form of analog forecasting,
and analog forecasting is meteorological version of CBR.
Huschke (1959) defines persistence forecast as: "a forecast that the future weather conditions will be the same as the present conditions." Huschke (1959) defines climatological forecast as: "A weather f
orecast based upon the climate of a region instead of upon the dynamic implications of the current weather. Consideration may be given to the climatic behavior of such synoptic weather features as cyclones and anticyclones, fronts, the jet stream, etc.&q
uot; The time of year (i.e., Julian day) is a condition that strongly determines the evolution of weather, on both the large scale and the local scale. 27
Martin (1972) explains how PC combines persistence and climatology to forecast cloud ceiling and visibility. We summarize his description as follows. The basic objective of PC is to answer the question: In similar past situations, what were the outcomes 1, 2, 3,... hours later? PC is a meteorological application of joint probability. For example, sup
pose that it is 6 am in June and the airport is "socked in" in fog. The flying category is the lowest possible, Category 1. Using PC, one tabulates before-the-fact probabilities (prior probabilities) to forecast for such a situation. The data
base is searched for all instances of {June, 6 am, flying category 1}, the flying categories during the subsequent hours are tabulated, and probabilities were prepared accordingly. The elements of PC forecasting are shown in Figure 6. For purposes of illustration, the weather data are simplified. 28 Only four attribut
es are shown. In practical systems, many more attributes may be used. The present case is the incomplete present case that we want to predict for. The predictands are the missing parts of the present case, what we want to predict. The past case is an archived case which nearly matches the known attributes and auxiliary predictors of the present case. The auxiliary predictors are information about the present case available from sources other than direct observation, such a
s NWP or human estimation. present case past case time
cloud
visibility
dew
wind
cloud
visibility
dew
wind
00h 210 2400 20 190
°
10 90 2400 20 190
°
12 01h 90 2400 20 200
°
11 120 2400 20 200
°
11 02h 120 12800 20 230
°
11 120 3200 20 210
°
10 03h 150 3200 20 230
°
8 150 4800 20 220
°
9 04h 210 16000 19 210
°
9 210 6000 19 230
°
8 05h 300 16000 18 320
°
6 240 7200 18 320
°
7 06h 240 19200 18 320
°
5 300 19200 18 320
°
6 07h unlimited 24000 17 330
°
5 4000 24000 17 330
°
6 08h 7500 24000 16 330
°
6 7500 24000 16 320
°
6 09h 7500 16000 16 310
°
7 7500 24000 16 310
°
6 10h 7500 19200 15 290
°
5 7500 24000 15 300
°
6 11h 7500 19200 15 290
°
9 7500 24000 15 290° 12h 7500 24000 14 290
°
6 7500 24000 14 290
°
6
These two are These three may be anticipated with
In a forecast setting, grayed-out values are Figure 6. Persistence climatology (PC) bases predictions for the present case on the outcomes of similar past cases. For example, two simplified series of hourly weather observations are listed. The present case is based on
actual observations from Halifax International Airport (from September 12, 1999). The past case is a hypothetical analogous case. 29 PC makes predictions from such analogous past cases. In an actual forecast settin
g, the attributes of the present case would only be known up until 04h, whereas attributes of the analogous past case are known for the entire time span. Note that after 04h, in both cases case, the wind veers suddenly to northwest, dew point temperature
s fall sharply, and low cloud clears quickly. Certain near-term attributes of the present case, such as dew point temperature and wind, may anticipated using auxiliary predictors from existing objective prediction techniques (e.g., numerical weather pred
iction).
Because analog forecasting is fundamentally different from NWP, it complements NWP. Therefore, analog forecasting has potential applicability for postprocessing of NWP output. Postprocessing of NWP output is the process of c
ombining NWP output with complementary information and forecasting techniques. 30
1.5.3.5 Fuzzy k-nn based forecasting: Analog forecasting without built-in constraints
The fuzzy k-nn technique can free persistence climatology (PC) from two of its main limitations and thus make PC more flexible and better able to take advantage of available data. The two limitations on the flexibility of pre
vious PC systems are: · Previous PC systems treat weather as if it was categorical, (and therefore)
One problem with representing weather cases according to the membership of those cases' attributes in crisp categories (as all previous PC systems do) is that such categories may not accurately reflect the level of similari
ty between cases, as illustrated in Figure 7. Figure 7. Crisp categories may not accurately reflect the level of similarity between cases. Such categorization may produce counterintuitive results. For example, the values of points A and B are similar and the values of
points B and C are dissimilar, but points A and B fall into different categories and points B and C fall into the same category.
Another problem with using crisp categories to represent weather cases is that, as the number of stratifying conditions increases and as specified events become rarer, instances for statistical tabulation may not exist. Martin (1972
) attributes the problem to "rare events," but, to be more exact, the problem is that the more precise a crisp range query is, the greater the chance of finding no match. Therefore, previous PC systems have only used, or taken advantage of, a l
imited number of predictors so as not to produce "empty bins." 31
All gardeners are familiar with crisp climate classification schemes, or "growing zones," and understand how such schemes are simplistic and potentially misleading. 32 McBratney and Moo
re (1985) applied fuzzy logic to the problem of climatic classification. From their results, they found: it appears the fuzzy sets approach has a useful place in climatic classification," [and suggest three reasons for the efficacy of fuzzy sets approach are that it] is realistic, flexible, and may offer
better approach to information transfer than does the classification of climate into discrete sets. We agree. McBratney and Moore (1985) emphasize that climate variables are continuous and that boundaries, if they exist, are fuzzy. They suggest that the apparent arbitrariness of [conventional, crisp] climate classification suggests an alternative approach would be the storage of climatic data in easily accessible form and the generation of a specific
`classification' for a particular purpose when it arises, using multivariate techniques. Our fuzzy k-nn algorithm follows this suggestion to gear the algorithm for a particular purpose. It searches the stored weather observations and retrieves the k-nn which most belong to the mom
entarily most important class of weather observations, a class whose centre is defined by the features of the current weather situation, the latest series of airport weather observations.
We reviewed the meteorological literature on airport weather prediction systems and found only two systems that demonstrated accurate prediction results comparable to the benchmark prediction technique of persistence forecasting. · Wilson and Sarrazin (1989) describe a refinement of PC called "SHORT" (the name is unexplained) that performs very well. SHORT describes the climatology of changes in aviation w
eather parameters based on 30 years of record. SHORT is more skillful than "conditional climatology" at all forecast ranges. SHORT is apparently still unrivalled by any other category-based PC system and is undergoing continued development.
Despite their obvious skill, both systems have what we perceive to be design flaws which are inherent in all category-based and thus category-constrained PC systems to date. Wilson and Sarrazin (1989) explain, in SHORT, &q
uot;all predictands and predictors are categorized," and proceed to illuminate two problems arising from the use of categorization. First, there is not a single, consistent method to choose "best" categories. The "best" categori
es vary from one situation to another. Many strategies are available for choosing `best' categories, the definition of `best' depending on the use of the forecast. (Wilson and Sarrazin, 1989) Second, categorization loses detailed information. The categorization procedure is considered necessary because the [multivariate linear regression] procedure produces large volumes of probability forecasts for each station and projection time. This proce
dure effectively summarizes the information but also makes the category decision for the forecaster and loses the detailed information available from probabilities. (Wilson and Sarrazin, 1989) When Wilson and Sarrazin (1989) speak of loss of detailed information, they refer only to loss at the output stage, but the same sort of loss occurs at the input stage. SHORT processes data in
three stages: 1. It receives many detailed cases and converts them into categories, thus discarding detailed information about similarity between weather cases at the input stage.
Wilson and Sarrazin (1989) recommend trying new graphical output procedures to recover some of the information lost at the output stage. But the detailed information about similarity between cases lost at the input stage t
o multivariate linear regression due to categorization is irretrievable. Details that could enable the measurement of level of similarity of analogous cases are discarded through categorization.
Another problem inherent in both SHORT (Wilson and Sarrazin 1989) and OBS (Vislocky and Fritsch 1997) is that they do not incorporate into the prediction scheme numerous real-time predictors, such as data from surrounding weather-mea
suring stations or from upper air stations. There is a practical limit on the number of combinations of attributes that statistics can be prepared for. The size of the equation set tends to grow exponentially with the inclusion of each new attribute.
In contrast, the fuzzy k-nn system grows linearly in complexity as new attributes are added (illustrated in Figure 9, page 64). Thus, it can po
tentially take better advantage of many valuable real-time predictors-variable, situation-specific predictors that are relevant to current weather. Operationally, forecasters know more than what month it is and what time of day it is. They have addition
al knowledge about what the "problem of the day" is. For example, if a cold front is due to pass through the region during a forecaster's shift, then all weather timings hinge on the time of passage of a cold front. "Timing the cold front
" and its associated wind shift is the most critical task for an aviation forecaster on such a day.
Timing of fog and ceiling lifting often depends on the passage of a cold front. For instance, forecasters may determine, either manually or automatically, that wind direction will shift from 160° to 320° three hours after
forecast time. Fuzzy k-nn analog forecasting can begin with that information. It searches the record of over 300,000 consecutive hourly airport reports for the few most similar situations in the past, similar according to all the commonly known a
ttributes plus the very predictive information about wind direction shift three hours hence. Those few analogs are most relevant and excellent for prediction.
Presently, with PC, there is not an easy way to specify such a peculiar set of conditions as {June, 6 am, 1/4SM FG, OVC001, wind shift from 160° to 320° three hours hence}, because PC must be prepared before-the-fact
, using only a limited set of commonly used predictors. Information about such peculiar cases, contained in the database, is not presently made available to forecasters. It is impractical to prepare PC statistics for the full range of possible situation
s and relevant predictors. Whereas, the fuzzy k-nn technique can select the k-nearest neighbors, nearest in terms of a set of critical attributes (i.e., predictors) which can be known only at forecast time.
From a user's perspective, fuzzy k-nn is flexible. A meteorologist colleague of ours described it as "custom climatology on-the-fly." A system can defer important decisions until run-time. A forecaster invests con
siderable effort in timing a cold front. The forecaster could use "real-time persistence climatology" simply by entering the precise expected wind-shift attributes into a system, let the system automatically supply the other predictors (e.g., t
ime of day, month, surface observations, NWP), and have the system output the likeliest trend of ceiling and visibility using all the available data and the best analogs.
To the best of our knowledge, "pure analog forecasting" has never before been used to produce airport weather forecasts. By pure analog forecasting, we mean making forecasts based on a few actual most similar cases,
similar according to the salient attributes of the present case and selected from an entire archive, rather than making forecasts based on statistically derived probabilities, probabilities that are determined according to general attributes of many case
s.
All work to date to automate airport weather prediction has used some combination of all of the three methods: climatology, numerical weather prediction (NWP), and statistics. Climatology describes the past behavior of specific weat
her conditions at an airport. NWP provides guidance about near-term future conditions. Statistics let us calculate conditional probabilities. A system combining these three methods is often referred to as model output statistics (MOS). 34 All such MOS work is based on two assumptions: 1. Analog forecasting: good analogs make good predictions. Similar weather situations, patterns and sequences, behave similarly.
We will use the first assumption because we believe it's a principle with wide applicability. However, we will not use the second assumption. We claim that it is a compromise, an oversimplification of data, that has becom
e increasingly unnecessary. In the past, with relatively limited computing power, to process large weather databases, it was necessary to greatly condense them, to preprocess them before the reception of up-to-the-minute predictive information. The fuzz
y k-nn method can process large databases efficiently after the receiving the specific details of a new case and thereby perform unconstrained analog forecasting.
1.5.3.6 Fuzzy k-nn algorithm's improvement to analog forecasting
Our fuzzy k-nn algorithm can improve analog forecasting because the flow of weather is sensitively dependent on initial conditions. The fuzzy k-nn identifies the most similar cases regardless of categories. Previous a
nalog forecasting techniques used predefined categories and thus must have failed to measure sensitively dependent conditions.
Analog forecasting of aviation weather using the fuzzy k-nn algorithm is more flexible and, thus, potentially more useful than previous category-based analog forecasting systems.
Previous analog forecasting systems: assume a limited number of predictors, represent attributes of cases according to their membership in categories, and prepare probabilities of categorical events accordin
gly. Whereas fuzzy k-nn based analog forecasting can: use any predictors which are available at run-time, represent attributes of cases with their full measured precision (thereby preserving information that improves similarity measurement), and p
repare analog predictions based on a few individually-weighted, most-similar temporal cases.
Using the fuzzy k-nn method frees us from the dependence on the assumption (implicit in all previous attempts to automate airport weather prediction) that similarity can be adequately described according to membership of case
attributes in a few, arbitrary, crisp, predefined categories. The consequence of categorization of case attributes-when categories are defined for general situations, without regard to specific cases or case-specific contextual information-is that precis
ion of distance measurement between analogous cases is reduced. Categorization is "lossy," so to speak. However, attempts to circumvent the problem of lossy categorization by creating more and finer categories simply leads to another problem:
the increased chance that there will be too few instances to base probabilities upon. In contrast, the fuzzy k-nn method avoids categorization and both of its related problems by, in the sense of (Viot 1993), fuzzifying input and defuzzying output
.
To the best of our knowledge, the fuzzy k-nn technique described in this thesis is the only example of the use of a proper distance function and metric space being used for airport weather prediction. This is fu
rther explained in Chapter 2. 35
In Chapter 2, we survey how others have used fuzzy logic for retrieval. In Chapter 3, we describe our implementation of a fuzzy k-nn algorithm
for airport weather prediction. 1 The opening statement is the thesis of this thesis. Specific support for this statement can be found in a number of articles that we review in Section 2.4 o
n page 65 (namely: Bonissone and Ayub 1992; Bonissone and Cheetham 1997; Cheetham and Graf 1997; Göös et al. 1999; Hansen and Riordan 1998; Lefley and Austin 1997; Main et al. 1996; Tobin et al. 1998; Web
er-Lee et al. 1995; Winder et al. 1997). 2 The Interdisciplinary Workshop On Similarity And Categorisation (SimCat 97), held at the University of Edinburgh in 1997, was "a gathering of researchers addressing similarity and categorisation from
a wide range of disciplines, including: artificial intelligence, machine learning, case-based reasoning, psychology, philosophy, linguistics, statistics, semiotics, music, [and] design theory." (Description of workshop downloaded from
http://www.dai.ed.ac.uk/conferences/simcat April 18, 2000)
A book that reprints 51 papers by different researchers is: Dasarthy, B. V. (ed.) 1991, Nearest Neighbor Pattern Classification Techniques, IEEE Computer Society Press, Los Alamitos, CA. All the pattern classification deals w
ith static images, or multi-dimensional cases. There is no explicit coverage of time dimension, or prediction. However, the preface does say that "NN concepts are being applied in new environments outside traditional pattern recognition." 3 All of the CBR systems surveyed by Kolodner (1993) come from research based in the United States, a fact subsequently pointed out by European researchers (López de Mántaras and Plaza 1997).
There was apparently in the early 1990's a little rivalry between the "first school" of cognitive science based CBR researchers, based in the United States, and the "second school" of application oriented CBR researchers, based in Euro
pe. 4 Aha (1998) explains that k-nearest neighbor (k-nn) classifiers that use similarity functions to answer queries are a frequently studied group of "lazy learners." Aha (1998) divides
learning algorithms into two categories: eager and lazy. Eager learning algorithms process data before receiving queries and any related new data. Such processing converts large amounts of data into compact abstractions such as rule sets,
decision trees, or neural networks. Whereas, lazy learning algorithms process data after receiving queries and any new data, and can thus take advantage of last-minute information.
The fuzzy k-nn system described in this thesis may be viewed as a pure lazy learner. The system uses precise information about present cases-information that is only available in the context of the present-to inform the searc
h for similar past cases. Anyone who is asked to find similar cases would naturally ask: Similar to what? The present case answers that question and is the basis of the query. 5 Fuzzy logic is used in thousands of applications, in areas such as: transportation, automobiles, consumer electronics, robotics, computers, computers, telecommunications, agriculture, medicine, management,
and education (Munakata and Jani 1994). 6 Zadeh (1965) first defined a fuzzy set as follows: "A fuzzy set is a class of objects with a continuum of grades of membership. Such a set is characterized by a membership (characteristic) function w
hich assigns to each object a membership ranging between zero and one." 7 NAV CANADA is the agency that manages Canada's air navigation system-including air traffic control, flight information, weather briefings, airport advisory services and electronic aids to navigation. 8 In the Experiments chapter, we will measure the accuracy of fuzzy k-nn based predictions with the same statistics that are used by NAV CANADA and described b
y Stanski et al. (1999). 9 By "bad weather," we mean weather conditions that complicate flying, such as low cloud ceilings or low visibility. Low visibility is caused by various factors, such as fog or snow. Such conditi
ons may slow or stop airplane traffic, just as fog affects the way motorists drive. Even though large airplanes can land with little visibility, such conditions commonly cause expensive traffic problems. Traffic problems at one airport can "ripple&
quot; through the entire air transportation network and cause scheduling problems for distant airports. 10 Patton (1996) represents one common set of pilot decision-making behaviors with a decision tree with over 100 nodes. 11 All financial figures in this thesis are in Canadian dollars unless stated otherwise. Environment Canada currently receives about $24 million in annual revenue from NAV CANADA for the provision of aviati
on weather services (Macdonald 1999). The provision of TAFs accounts for about 20% of this revenue (Meadows 1997). The contract between EC and NAV CANADA specifies accuracy and timeliness targets for TAFs. The current contract between EC and NAV CANADA
will expire in November 2001, after which time NAV CANADA may seek tenders for aviation services. NAV CANADA is naturally concerned with minimizing its costs and passing along any savings to its clients and stakeholders. It is logical to expect that NAV
CANADA will want a better deal when they go to tender. 12 The fact the Conway (1989) found many fewer AI-meteorology papers than Christopherson (1998) is partly explainable by the facts that: (1) Conway's survey focused on expert systems, rather than AI, and (2)
some additional meteorology application papers identified by Conway, while "AI-like," were not billed as AI. Even so, it is obvious that AI-meteorology papers are becoming increasingly numerous. 13 The first two challenges are not dealt with directly in this thesis. Convenience and speed are operational concerns. Pattern recognition problems relate mostly to image interpretation-Bezdek and Pal (19
92) offer a large collection of papers which describe how to use fuzzy models for pattern recognition. We plan to attend to these special challenges in future related work. 14 Gershon and Miller (1993) estimated, "By the year 2000, satellites deployed by the National Aeronautics and Space Administration will be transmitting 1 terabyte of data to earth every day." 15 Forecasters often apply complex forecasting techniques when simple short-tern persistence forecasting would probably produce more accurate forecasts. In a comparison of simple persistence forecasts with
human-produced forecasts, Dallavalle and Dagostaro (1995) report that, "Generally persistence forecasts appeared to have higher skill than the local forecasts for the 3-hour projection." This tendency that people have to solve simple problems
with all the tools at their disposal is referred to as "over-forecasting." 16 Fuzzy rules typically operate on variables of different dimensions. For example, a rule for a furnace could be: if temperature is low and pressure is low then increase heat. Temperature and press
ure are expressed with different physical units, but the fuzzy rule operates on equally communicative fuzzy set representations of the variables. 17 Dyer and Moninger (1988), from a workshop on AI research in environmental sciences, note that "One speaker said that weather forecasting R&D in the 1940's and 1950's shared much in common with
the current AI thrusts, but that research was essentially shelved for 30 years as numerical weather prediction (NWP) took prominence.". Frankel et al. (1993), from another workshop on AI needs in meteorology, note that a representative of the Meteor
ological Service of Canada emphasized the prominence of NWP: "A major thrust in Canadian meteorological research is the continued development of world class NWP models." 18 The section Additional references on analog forecasting in meteorology lists meteorology papers which describe the challenges of implementing analog forecasting. 19 Kumar et al. (1994) used the commercially available packages C4.5 and ID3. The system-specific details of how their systems built decision trees are not relevant in this thesis. What is relevant is that
they used decision trees that split data into crisp sets. Our fuzzy k-nn algorithm does not split data into crisp sets and, therefore, appears to be unique among weather forecasting applications. 20 Apparently, from (Kumar et al. 1994), the current prediction method for Melbourne is a sort of "man-machine mix." Forecasters appraise, select, and use whatever information or guidance is avail
able, and the most relied-upon guidance is statistical (climatology plus NWP). 21 "When it is evening, ye say, `It will be fair weather: for the sky is red.' And in the morning, `It will be stormy today, for the sky is red and lowering.'" (Matthew 16:2-3) 22 The above description of analog forecasting is from "Online Guide to Weather Forecasting" at the University of Illinois Department of Atmospheric Sciences
(http://ww2010.atmos.uiuc.edu/(Gl)/guides/mtr/fcst/mth/oth.rxml, downloaded on March 25, 1999). 23 In Lorenz' experiments, "long-term" pertained to prediction of upper atmospheric fields days in advance. Aviation weather changes more rapidly, so in the context of this thesis, predictions six
to twelve hours in advance can be thought of as "long-term." 24 Van den Dool (1994) estimated that it would take on the order of "1030 years to find analogues that match over the entire Northern Hemisphere 500 mb height field to within current observat
ional error." The 500 mb (millibar) height field is a pressure field in the upper atmosphere, at about 6 km altitude, which is commonly examined by weather forecasters. 25 For this thesis, we do not need to concern ourselves with phase space and dimension determination problems because we: 1) have a large, representative record of a multidimensional time series, 2) know man
y of the relevant dimensions, 3) intend to straightforwardly perform analog forecasting (Lorenz 1969a), 4) do not intend to model the signal into uncharted space, and 5) do not intend to model the signal far into the future. We will simply collect an ens
emble of analog trajectories and make reasonable inferences about the course and the predictability of short-term conditions. Nevertheless, the reader may be interested in the following technical chaos-related terms. A phase space is a coordinate
space in which the coordinates are temporally related (e.g., x and dx/dt). Such a space can specify the state of a dynamical system. For example, simple harmonic motion is a circle in the phase plane. The dimension of the model is
the number of coordinates needed to specify a state. When analyzing single scalar signals from systems with an unknown number of dimensions of freedom, a number supposedly greater than 1, some mathematical techniques, which are outside of the scope of t
his thesis, are necessary to estimate the dimension. For example, reconstructing the phase space through the technique of time delay embedding is a systematic way of transforming scalar data to a multidimensional phase space (Aberbanel et al. 1993). 26 Pure persistence is not much of a model but it is effective nonetheless (see our Additional references on analog forecasting in meteorology). Interestingly, proponents of CBR often cite the model-
free quality of CBR as an advantage. Models are difficult to construct in areas where domain theory is weak or domain experts are unclear. 27 Barry and Chorley (1968) explain large-scale weather patterns correlate to particular dates: Recurrent weather spells about a particular date (singularities), such as the tendency for anticyclone weather in mid-September, have been recognized in Britain and major seasonal trends in occurrence of airfl
ow regimes can be used to define five natural seasons [in Britain.] ... Three major North American singularities concern the advent of spring in early March, the midsummer northward displacement of the sub tropical high-pressure cell, and the Indian summe
r of September-October. 28 The weather data are from weather observations (METAR code) for Halifax International Airport for the period from 00:00 to 12:00 UTC September 12, 1999. 29 We assume that the principle of analog forecasting is applicable and, therefore, assume that the weather archive, which is composed of 13,149 days of past cases, contains analogs for the present case. Fo
r purposes of illustration, in Figure 6, we contrive a simple analog. However, in our experiments, we will only compare actual cases. 30 Cats and Wolters (1996) describe postprocessing of NWP as follows: "Modern numerical weather forecasting systems have three basic components: an analysis unit, a forecast model, and a postprocessor.
... In the postprocessing step, the relevant weather phenomena (for example wind speed at 10 m height are calculated from the model variables." In our case, the relevant weather phenomena are cloud ceiling height and horizontal visibility. 31 This is reminiscent of the "accuracy-versus-precision" tradeoff in weather prediction. That is, the more precise a prediction is, the less chance there is that it will be accurate. In the case
of data base querying, the more precise a query is, the less chance there is that a matching item will be found. 32 In a gardening encyclopedia, Bradley and Ellis (1992) explain "growing zones" as follows: "In order to help growers determine which plants are best for their regions, the USDA's [US Depart
ment of Agriculture] Agricultural Research Service developed a Plant Hardiness Zone Map. ... It divides the United States and southern Canada into 11 climatic zones, based on the average annual minimum temperature for each zone. Zone 1 is the coldest, mo
st northerly region, and Zone 11 is the warmest, most southerly. ... Keep in mind that there are climatic variations within each region and even within each garden. Your garden's immediate climate may be different from that of the region overall. Many f
actors-altitude, wind exposure, proximity to bodies of water, terrain, and shade-can cause variations in growing conditions by as much as two zones in either direction." Thus, for example, although general growing conditions in Nova Scotia are Zone
5, local growing conditions may range from Zone 3 to Zone 7. 33 There are numerous airport weather prediction systems described in the literature (e.g., Clarke 1995; Garner 1995; Gollvik and Olsson 1993; Keller et al. 1995; Kilpinen 1993; Kumar et al. 1994; Meyer 1995
; Porter and Seaman 1995; Shakina et al. 1993; Warner and Stoelinga 1995; and Whiffen 1993), but none of these works claim to be as nearly as skillful, significant, or practical as the two referred to above, SHORT (Wilson and Sarrazin 1989) and OBS (Vislo
cky and Fritsch 1997). 34 Strictly speaking, "MOS" has a more restricted meaning in meteorology. Depending upon the approach towards climatology, NWP, and statistics, a hybrid method may be referred to differently, e.g
., "persistence climatology" (Martin 1972), "SHORT" (Wilson and Sarrazin 1989), "OBS" (Vislocky and Fritsch 1997), and "perfect prog" (Stern and Parkyn 1999) to name just a few. But such meteorological semantics ar
e beside the point. The point is that all serious attempts to automate airport weather prediction: Combine three basic prediction methods: climatology, NWP, and statistics.
35 For definitions of proper distance function and metric space, see footnote number 42 ahead on page 52.
Inference Engine
Knowledge Base
· Reuse the information and knowledge in that case to solve the problem.
· Revise the proposed solution if necessary.
· Retain the parts of this experience likely to be useful for future problem solving.>
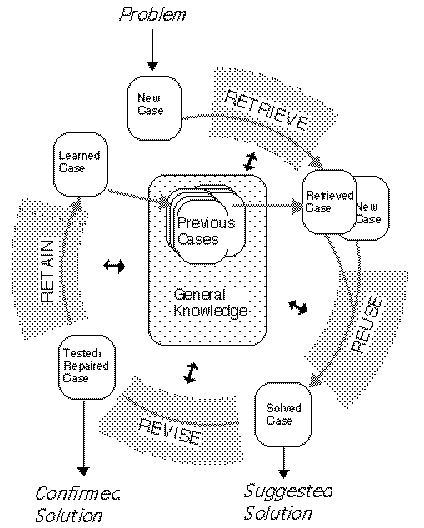
· Case authoring: developing methods for preparing cases for inclusion in a case base, e.g., developing tools to enable an expert to participate directly in the case acquisition and case engineerin
g process.
· Scaling up systems to large problems.
· Problems with libraries of many cases.
· Fuzzy logic is well-suited to modelling continuous, real-world systems. Many systems dealing with environmental data use fuzzy logic (Hansen et al. 1999).
· Fuzzy logic has a "tolerance for imprecision which can be exploited to achieve tractability, robustness, low solution cost, and better rapport with reality.&
quot; (Zadeh 1999).
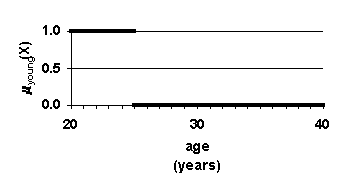
(a) Crisp set for young.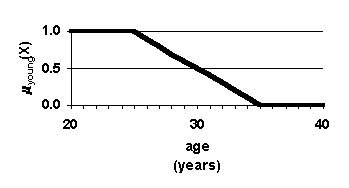
(d) Fuzzy set for young.
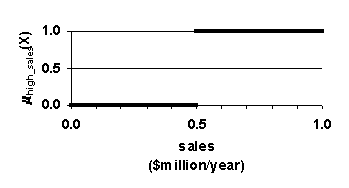
(b) Crisp set for high sales.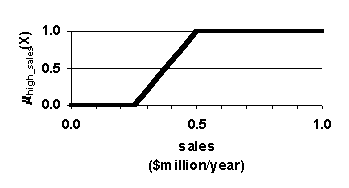
(e) Fuzzy set for high sales.
(c) Crisp decision surface for
young with high sales.
(f) Fuzzy decision surface for
young with high sales.
· "A large scale-knowledge base can be effectively handled and reduced by fuzzy front-end processor, making [neural network] learning easy and fast-non-precise and context dependent knowledge
is represented using fuzzy logic."
· "Recognition and learning from noisy data is possible."
· "The technique is robust in that only some rules in knowledge in fuzzy knowledge base require to be updated with changing input conditions, avoiding the need to retrain the neural network.&q
uot;
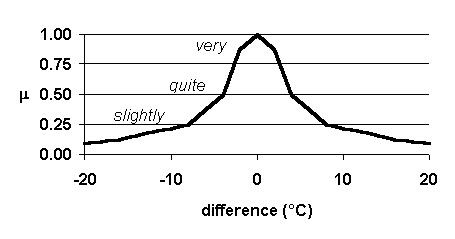
· Timeliness of revision. This describes the length of time from the detection of weather conditions contradicting TAF (i.e., a forecast "going bust") and the delivery of a suitably revised forecast.
· The loss of TAF coverage at any particular airport would increase planning difficulties for managers at that particular airport.
· Pattern recognition problems.
· Missing and conflicting data.
· Similarity can be evaluated using fuzzy sets.
2. "The lack of a single computer environment in the field that has the power and flexible access to integrate diverse, complex or very large, non-static datasets. This is especially true because domain experts (met
eorologists) are rarely system programmers, or academically trained in AI."
3. "The AI development process is inherently an engineering process rather than a scientific investigation. Meteorologists are trained to do the latter and commonly avoid or even scorn the former."
4. "AI is often non-linear (subtle changes in input yield large changes in output). It is also not based on a physical model of the problem domain. This deters meteorologists, who want algorithmic solutions that mo
del the atmosphere."
5. "While AI techniques are a broad and versatile technology, most applications solve narrow problems. Changing anything requires an entire developmental re-work to regain any skill and may require substantial changes in s
ystem design."
6. "The often specific nature of AI solutions suggest they are best used at the [regional] forecast office rather than the national center. However, the forecast office has traditionally been ill equipped to work with suff
iciently detailed data sets and there has been a lack of sufficiently detailed data sets."
7. "AI will not be accepted until it is developed, taught, and used in university and college meteorology programs and government research laboratories and training facilities."
· It is difficult to discover through forecasting experience how to make near-optimal forecasts.
· Forecasters themselves express uncertainty about how to best use available forecast guidance information. Even experienced forecasters do not know how to best use guidance information.
· Some forecast verification statistics do not show any improvement in forecast skills over recent decades despite improvements in the quality and quantity of guidance information over the same tim
e interval.
Red sky at night, sailors delight. (Anonymous)
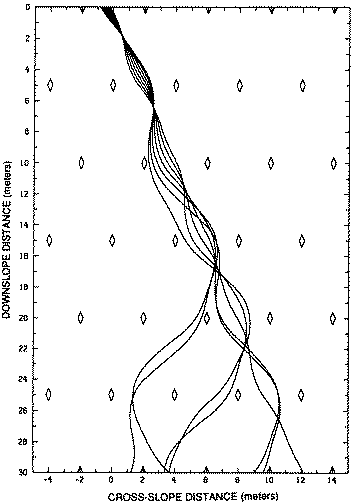
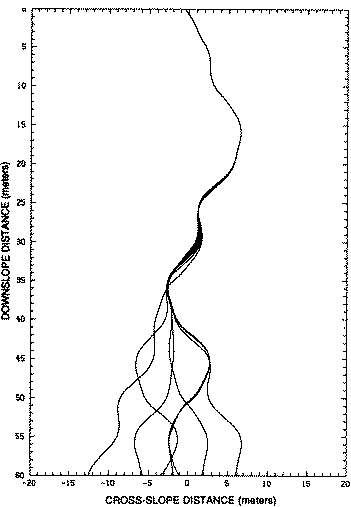
spaced at 10 cm intervals.
spaced at 1 mm intervals.
· "This article is designed to bring scientists and engineers a familiarity with developments in the area of model building based on signals from nonlinear systems. The key fact that makes this
pursuit qualitatively different from conventional time series analysis is that, because of the nonlinearity of the systems involved, the familiar and critical tool of Fourier analysis does very little, if any, good in the subject. The Fourier transform
of a linear system changes what might be a tedious set of differential equations into an algebraic problem where decades of matrix analysis can be brought to bear. Fourier analysis of nonlinear systems turns differential equations in time into integrals
in frequency space involving convolutions among the Fourier transforms of the dependent variables. This is rarely an improvement, so Fourier models are to be discounted at the outset, though as an initial window through which to view the data, they may p
rove useful."
· "It is not uncommon to see attempts to overcome the limitations imposed by small data sets by measuring the system more frequently. ... this is not an effective tactic. The raw number of poi
nts is not what matters; it is the number of trajectory segments, how many different times any particular locale of state space is visited by an evolving trajectory, that counts."
· "Our task is to find points in our sample library that are very close together and watch how trajectories specified by following points separate. In locating the initial neighboring points we
must not consider points that are from the same temporal segment of the library."
· [Regarding local modelling] "We now assume that our data are embedded in an appropriate phase space, and we have determined the dimension of the model. [25] The problem is now to reconstruct the deterministic rule underlying the data. We start our discussion with the simplest and earliest nonlinear method of local forecasting, which was suggested by E. Lorenz (1969b). Let us
propose to predict the values of y(k+1) knowing that a long time series of y(j) for j
£
k. In the `method of analogs' we find the nearest neighbor to the current value of y(k) say, y(m) and then assume that y(m+1) is the predicted value for y(k+1). This is pure persistence and is not much of a model." 26 To improve the quality of this prediction, Abarbanel et al. (1993) suggest to take a collection of near neighbors of the point
y(k) and predict an averaged value of their images, and suggest to weight the neighbors to provide a larger contribution from close points.
· "Numerical results are critical to the study of nonlinear systems that have chaotic behavior. Indeed, computation plays a larger role in such studies than is traditional in many parts of the
physics literature. Progress such as that reported throughout this review rests heavily on the ability to compute rapidly, and as such would not have been possible a decade ago. The subject reviewed here is almost `experimental' in that sense through it
s reliance on computers as an instrument for its study. This bodes well for further analysis of chaos and its physical manifestations , since no one can expect even more powerful computers to be available on a continuing basis."
· "It would be enormously useful, for example, in the analysis of data to have some estimate of the error in all the conclusions arising from finite data sets as well as from numerical, experime
ntal, or instrumental uncertainty."
· "The discovery of temporal chaos in physical systems is a `finished topic of research,' we believe. Many physical systems have been shown to exhibit chaotic orbits, and we are certain many mo
re will be found. It is no longer enough, however, to have good chaos, one must move on and extract good physics out of it."
(UTC)
ceiling
(m)
(m)
point
temp
(°C)
direction
(degrees)
speed (kts)
ceiling
(m)
(m)
point
temp
(°C)
direction
(degrees)
speed (kts)
predictands
auxiliary predictors
not known. They are objects of prediction.
· Previous PC systems can only use a very limited set of predictors.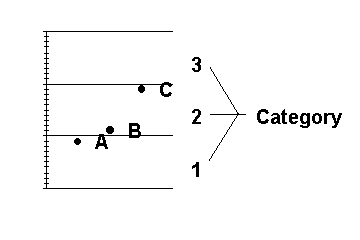
· Vislocky and Fritsch (1997) describe a refinement of PC called "OBS" (the name is unexplained) that performs very well. What is special about OBS is that it incorporates observational
weather data from surrounding airports, as well as from the particular airport in question, into the prediction process for the airport in question. Considerable skill is attributed to their unique inclusion of such highl
y relevant, predictive information. The authors suggest that further gains can be made in the future by somehow including more predictive information from other sources.
2. It develops regression equations based on categorical representations of cases.
3. It outputs the results of those operations into categorical predictions, thus losing the detailed information available from probabilities calculated during stage 2.
2. Similarity can be adequately described according to membership in a few, arbitrary, crisp, predefined categories.
Implicitly use the analog forecasting principle. For matching analogs, climatology gives hindsight about attributes of past analogous cases and NWP gives foresight about certain attributes of the present case. Statistics categ
orizes such attributes of past and present cases and makes inferences, or predictions.
And, prior to this thesis, implicitly assume that similarity, of new and unique weather cases with old weather cases, can be adequately described according to membership in a few, arbitrary, crisp, predefined, mediating categori
es, rather than by direct case-to-case comparison.![]()
![]()