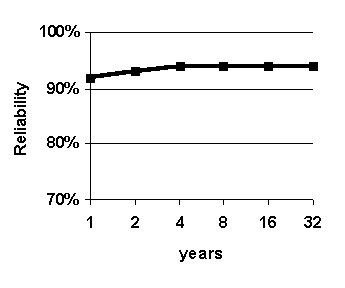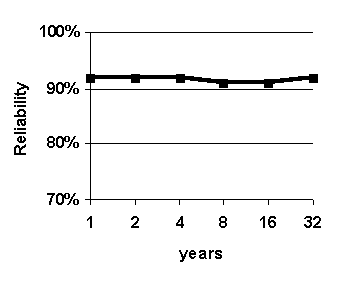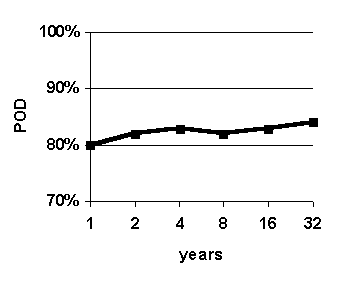![]()
![]()
![]()
The aim of our experiments is to test our hypothesis. 62 The previous chapter described the WIND-1 system, its components, and how it is configured. The algorithm for WIND-1 (shown in Figure 19 on page 90) is coded in C and implemented on a Hewlett Packard 9000 series workstation.
In this chapter, we evaluate the performance of the WIND-1 system by conducting a series of experiments, as is common current practice in machine learning algorithm validation, rather than simply by determining the plausibility of the results, as used to be common practice (Langly 1996).
This chapter describes a series of experiments that test the prediction accuracy of the WIND-1 system. Results of WIND-1 are measured using standard tests of prediction accuracy, presented in the form of graphs, and interpreted.
Results are presented in five sections. In section 4.1, we vary the attribute set in order to determine the relative predictive value of various predictors. In section 4.2, we vary the number of analogs used to make forecasts (k) in order to evaluate the tradeoff between using a smaller number more analogous cases and a larger number of less analogous cases and, thereby, select a good value for k. In section 4.3, we vary the size of the case base in order to assess the importance of having a large case base. In section 4.4, we decrease the level of fuzziness in the fuzzy sets in the fuzzy k-nn algorithm in order to assess the importance of fuzziness itself in similarity measurement And finally, in section 4.5, we test the prediction accuracy of WIND-1 against a benchmark prediction method, persistence.
Experiment design
Each experiment consists of a forecasting scenario. Five sets of experiments are conducted. In each set of experiments we systematically change the fixed parameters of WIND-1 and measure the resultant effects on forecast accuracy. The fixed parameters (independent variables) are: the attribute set, the number of analogs used to make forecasts, the size of the case base, and the fuzzy membership functions (i.e., level of fuzziness in the similarity-measuring sets). The output (dependent variables) are, for each individual forecast, forecast values of cloud ceiling and visibility, and, for each set of experiments, a summary of the accuracy of all the forecasts made.
The first four sets of experiments serve a dual purpose. First, they test the contribution of individual components of the system. Second, they suggest how to adjust these components in order to maximize the accuracy of the system. The last set of experiments pits the system against a competitive prediction technique, persistence forecasting. 63
In most of the sets of experiments, the first 35 years of weather data (1961-1995) is used as the case base and the final year of data (1996) is used as a source of "new cases." Such data segregation prevents sharing of information between past and new cases. In one set of experiments (Section 4.3), however, we test the effect of reducing the size of the case base.
In each set of experiments, 1000 hours are chosen at random from the 1996 weather archive and are each used as an hour to produce a forecast for. So, in each set of experiments, 1000 simulated forecasts are produced. For purposes of comparison, the same 1000 randomly-chosen hours are used in each set of experiments. This is a control so that the effect of varying other input can be tested.
In each individual experiment, a case is taken from the 1996 data and is used as a present case. It is input to WIND-1. During the forecast process, the outcome of the present case is hidden from WIND-1. WIND-1 produces a forecast for the present case based on the outcomes of the k-nn in the case base, the k most analogous past cases for the present case. After the forecast process, the accuracy of the forecast is verified by comparing the forecast with the then unhidden outcome of the present case. 64
Verification method
Each forecast is verified using standard measures of weather forecast accuracy, measures that are described in detail by Stanski et al. (1999), and summarized as follows.
Forecasts are verified according to the accuracy of forecasts of three significant flying categories, categories that are defined in Figure 24.
ceiling (m) |
visibility (km) |
flying category | ||
< 200 |
or |
< 3.2 |
Þ |
below alternate |
³ 200 |
and |
³ 3.2 |
Þ |
alternate |
³ 330 |
and |
³ 4.8 |
Þ |
VFR |
Figure 24. Flying categories.
Three sorts of prediction-versus-actual outcomes are counted: hits, false alarms, and misses. If an event is predicted and it occurs, it counts as a hit. If an event is predicted and it does not occur, it counts as a false alarm. If an event is not predicted and it does occur, it counts as a miss. How outcomes of forecast and observed events are classified is shown in Figure 25.
OBSERVED | |||
YES |
NO | ||
FORECAST |
YES |
hit |
false alarm |
NO |
miss |
non-event | |
Figure 25. How outcomes of forecast and observed events are classified. From the frequencies of these outcomes, three meteorological statistics are calculated: Reliability (i.e., Frequency of Hits, or FOH), Probability of Detection (POD), and False Alarm Ratio (FAR). Values are calculated as shown in Figure 26.
Reliability = |
FOH = |
hits / ( hits + false alarms) |
Probability of Detection = |
POD = |
hits / ( hits + misses) |
False Alarm Ratio = |
FAR = |
false alarms / (hits + false alarms) |
Figure 26. Formulae for verification of forecasts. Values of hits, false alarms, and misses are the summed outcomes of 1000 simulated forecasts. High levels of prediction accuracy are indicated by high Reliability, high Probability of Detection, and low False Alarm Ratio.
To ensure that WIND-1 verified its forecasts correctly, we double-checked the verification results. We had WIND-1 conduct a small set of experiments, based on only 10 forecasts, verified the forecast accuracy manually, and compared our manually-generated results with WIND-1's automatically-generated results. The results were the same.
The purpose of the first set of experiments is to determine the relative predictive value of various attributes (i.e., predictors) which are recommended by a forecasting expert. Seven sets of such attributes are listed in Figure 27.
Set |
Abbreviation |
Attribute set | |
1 |
cig & vis |
cloud ceiling and visibility (cig & vis) | |
2 |
pres + cig&vis |
pressure tendency, cig & vis | |
3 |
pcpn + cig&vis |
precipitation type and intensity, cig & vis | |
4 |
temps + cig&vis |
dry bulb temperature and dew point temperature, cig & vis | |
5 |
time + cig&vis |
offset from sunrise/sunset and date of year, cig & vis | |
6 |
wind + cig&vis |
wind direction and speed, cig & vis | |
7 |
all |
all of the above |
Figure 27. Attribute sets for matching. All attribute sets include cloud ceiling and visibility (cig & vis). The first set consists of only ceiling and visibility, the next five sets each consist of ceiling and visibility plus one other type of attribute, and the last set consists of all available attributes.
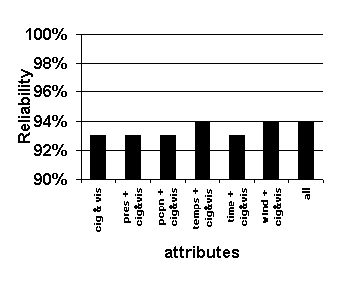
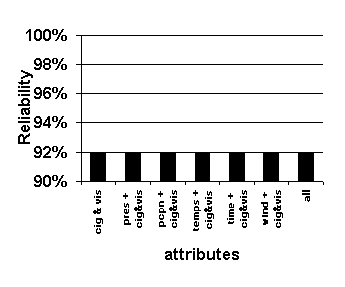
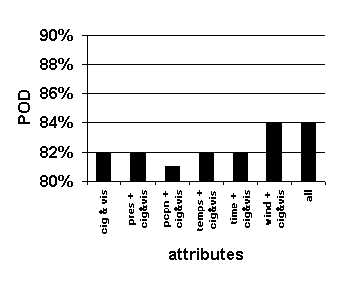
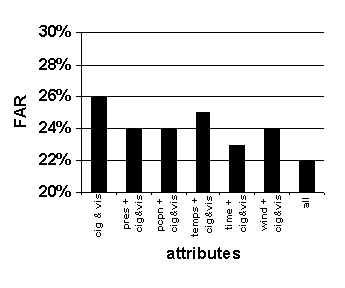
Because our objective is to predict ceiling and visibility, and because ceiling and visibility are known to be strongly autocorrelated, the attributes of ceiling and visibility are included in each attribute set. Figure 28 presents the results of varying the attribute set.
4.1 Effect of varying attribute set
|
|
(a) Reliability of "alternate" |
(b) Reliability of "VFR" |
|
|
(c) Probability of Detection |
(d) False Alarm Ratio |
Figure 28. Effect of varying attribute set. Graphed values are average accuracy of 0-to-6-hour predictions. System configuration: k =16, length of case base = 35 years.
The benchmarks for accuracy in each of the charts in Figure 28 are the left-most bars in each graph, the accuracy resulting from matching cases based only on their cloud ceiling and visibility attributes.
As attributes are added to the similarity measurement, the resulting accuracy of the forecasts tends to increase.
The best combination of attributes tested is the complete set of available attributes, the right-most bars in each graph. This combination results in the lowest False Alarm Ratio of below alternate (Figure 28 (d)) and ties for the highest values of probability of detection of below alternate, reliability of alternate, and reliability of VFR (Figure 28 (a), (b), and (c)).
The reliability of VFR is barely affected by the combination of attributes used (Figure 28 (b)). This is probably due to the climatological preponderance of VFR conditions in weather (conditions that are specified by cloud ceiling and visibility) and the strictness of the matching in the cloud ceiling and visibility conditions. VFR is the largest cluster of weather conditions and it is defined by the attributes of ceiling and visibility, so the contribution of other attributes is relatively small. In other words, it takes little skill to forecast the persistence of a most common condition: primary details (cloud ceiling and visibility) are sufficient to make accurate forecasts, and secondary details add little.
|
|
(a) Reliability of "alternate" |
(b) Reliability of "VFR" |
|
|
(c) Probability of Detection |
(d) False Alarm Ratio |
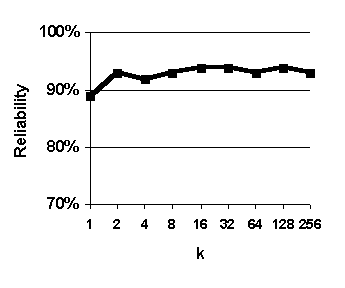
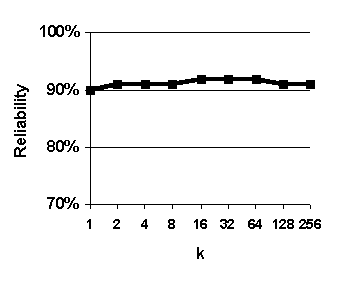
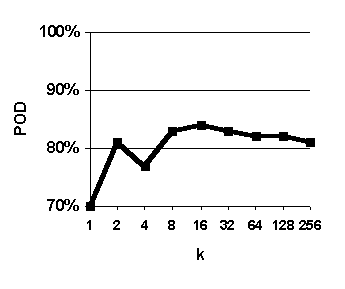
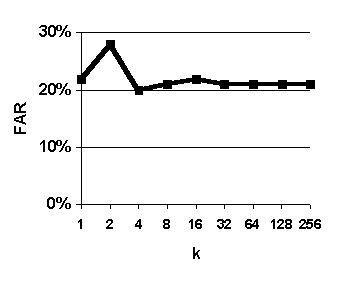
Figure 29. Effect of varying k. Predictions are based on weighted median value of k nearest neighbors. Graphed values are average accuracy of 0-to-6-hour predictions. System configuration: length of case base = 35 years.
The purpose of this experiment was to assess the effect of varying the number of analogous past cases used to make forecasts ("k" in the expression "fuzzy k-nn") in order to evaluate the tradeoff between using a smaller number more analogous cases and a larger number of less analogous cases, and thereby select a good value for k. We systematically varied the value of k and the results of this experiment are shown in Figure 29.
There is a peak in accuracy resulting from using 16 nearest-neighbor cases to form predictions, or about 0.005% (16 / 300,000) of all the available cases (Figure 29). This suggests the fuzzy k-nn algorithm is effective at identifying and ranking analogous cases; on average, the 16 nearest neighbors are more analogous and (and thus better bases for prediction) than the 256 nearest neighbors.
Accuracy tends to decrease as k decreases from 16 to 1. This suggests that it is more effective to base forecasts on small set of analogs than it is to base forecasts on single best analog. A similar effect is observed with "ensemble forecasting" technique in the field of numerical weather prediction in meteorology. 65
All the graphs show a peak for k=2. You might wonder why a peak would occur in all four charts (recall that that high values of reliability and probability of detection imply high accuracy and high values of false alarm ratio imply low inaccuracy). The reason is that reliability, probability of detection, false alarm ratio tend to rise together because of the way they are formulated. In practice, forecasters try achieve a balance between high reliability, high probability of detection, and low false alarm ratio. 66
4.3 Effect of varying size of case base
|
|
(a) Reliability of "alternate" |
(b) Reliability of "VFR" |
|
|
(c) Probability of Detection |
(d) False Alarm Ratio |
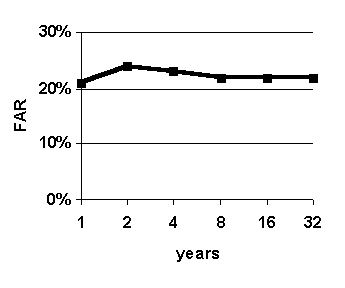
Figure 30. Effect of varying size of case base. Graphed values are average accuracy of 0-to-6-hour predictions. System configuration: k = 16.
The purpose of this experiment is to determine effect of varying the size of the case base in order to assess the importance of having a large case base. As the size of the case base increases, supposedly, more and more potential good analogs are available for the fuzzy k-nn algorithm upon which to base predictions. This experiment addresses the question: "Is the fuzzy k-nn predictions method effective with a small case base, or does it require a large case base?" This question is of practical importance because sizes of weather archives vary greatly from one airport to another. The size of the case base is varied and the results are shown in Figure 30.
Accuracy generally rises as the size of the case base size increases from 1 year to 32 years, although there appears to be a slight dip in accuracy for a case base size of 8 years (Figure 30 (b) and (c)). The general rise in accuracy suggests that having a large case base is beneficial. The slight dip in accuracy for a case base size of 8 years-though probably insignificant at 1%-may suggest that, for the purposes of predicting for weather situations in the year 1996, the four-year period 1992-1995 contains a higher proportion of good analogs than the 8-year period 1988-1995.
Significantly, the relatively high accuracy with a case base size of 4 years suggests that the WIND-1 system could be useful for predicting at airports with relatively small weather archives. Most airports have recorded weather for at least 4 years.
4.4 Effect of varying fuzzy set membership function
|
|
(a) Reliability of "alternate" |
(b) Reliability of "VFR" |
|
|
(c) Probability of Detection |
(d) False Alarm Ratio |
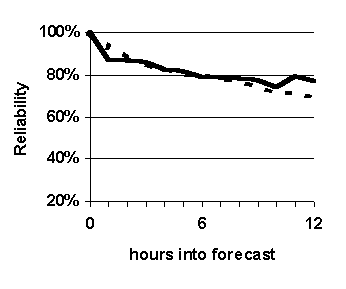
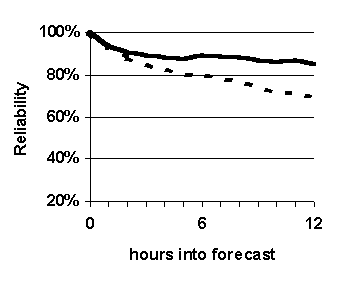
--- Non-fuzzy k-nn
|
Figure 31. Effect of varying fuzzy set membership function. Fuzziness is eliminated by converting elicited fuzzy sets into crisp sets. Graphed values are accuracy of prediction for each hour in the 0-to-12-hour projection period. System configuration: k=16, length of case base = 35 years.
The purpose of this set of experiments is to test the effect of using fuzzy sets in the similarity-measuring function, as opposed to using non-fuzzy sets. When we propose to use fuzzy sets in a similarity-measuring algorithm, we are often asked: "Why not use non-fuzzy category based similarity measures?" This set of experiments addresses that question by substituting non-fuzzy (i.e., crisp) sets for the previously used fuzzy sets. To eliminate fuzziness, we modify the function m fuzzy, as follows.
if m fuzzy < 0.5 then mcrisp = 0.0
else m crisp = 1.0.
Thus, for two cases, every attribute at every hour compared yields a similarity measure equal to 0 or 1. Then the overall similarity of the cases is determined by taking the average of all the attributes values. The results are shown in Figure 31.
Non-fuzzy k-nn based predictions are slightly more accurate than simple persistence based forecasts in terms of reliability and probability of detection (Figure 31 (a), (b) and (c)), and slightly less accurate in terms of false alarm ratio (Figure 31 (d)). The results supports what aviation weather forecasters commonly believe: It is difficult to beat simple persistence (forecasting "no change") in the short-term.
The non-fuzzy k-nn prediction scheme is essentially a form of conditional-persistence-based forecasting. 67 For cases to be in the nearest-neighbor set of the case being forecast for, the condition is that their attributes must fall within discrete, plus-or-minus ranges of the attributes of the case being forecast for. The results suggest that it is even difficult for conditional persistence to beat simple persistence.
|
|
(a) Reliability of "alternate" |
(b) Reliability of "VFR" |
|
|
(c) Probability of Detection |
(d) False Alarm Ratio |
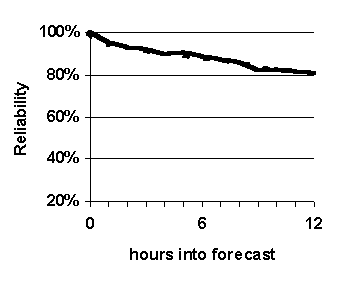
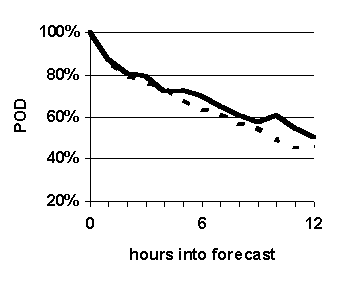
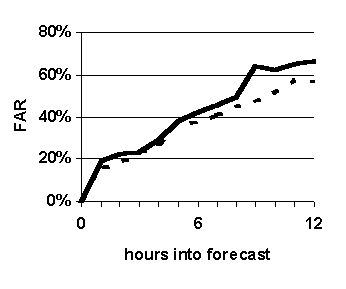
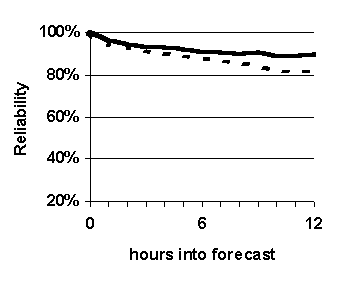
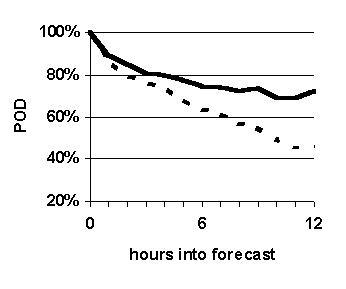
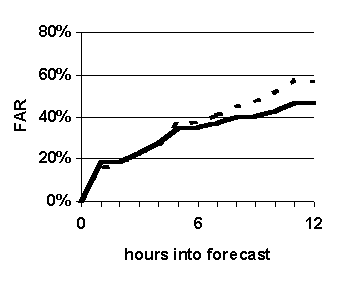
--- Fuzzy k-nn (WIND-1)
|
Figure 32. Accuracy of system compared to benchmark technique, persistence. Graphed values are accuracy of prediction for each hour in the 0-to-12-hour projection period. System configuration: k=16, length of case base = 35 years.
The purpose of this experiment is to compare the prediction accuracy of WIND-1 with that of the benchmark prediction method, persistence. The results are shown in Figure 32.
Fuzzy k-nn based predictions are significantly more accurate than simple persistence based forecasts in terms of reliability and probability of detection (Figure 32 (a), (b) and (c)), and generally more accurate in terms of false alarm ratio (Figure 32 (d)).
Fuzzy k-nn based predictions are significantly more accurate than non-fuzzy based predictions (compare Figure 32 with Figure 31). The only variation between the two experimental setups is the nature of the membership functions used to compare attributes. The fuzzy k-nn method uses fuzzy membership functions that span certain ranges around the case being forecast for; whereas, the non-fuzzy method uses 0-1-0 functions centered across the same ranges. This suggests that, compared to the accuracy of simple persistence, the significantly higher accuracy of fuzzy k-nn based forecasts is attributable to the use of fuzzy sets to measure similarity as opposed to using crisp sets. To the best of our knowledge, all previous methods used to measure similarity between weather cases have used only crisp sets.
62 Hypothesis: Querying a large database of weather observations for past weather cases similar to a present case using a fuzzy k-nearest neighbors algorithm that is designed and tuned with the help of a weather forecasting expert can increase the accuracy of predictions of cloud ceiling and visibility at an airport.
63 To be useful for airport weather prediction, a system should produce results more accurate than the results of persistence forecasting. To forecast persistence, one simply takes the known values of ceiling and visibility at time-zero, the beginning time of a forecast period, and assumes that they will not change through the forecast period,
Dallavalle and Dagastaro (1995) compared the skill of persistence-based forecasts with the skill of forecasts produced locally by the National Weather Service and found that "persistence forecasts appeared to have higher skill than the local forecasts for the 3-hour projection." When skill was considered for the six-hour projection, neither method was clearly superior; persistence had a higher Critical Success Index, but locally produced forecasts had a higher Heidke skill score.
64 During case-to-case comparison, we hid the outcomes of the present case so as not to "contaminate" our results. We did not give WIND-1 any prevision of attributes to guide its search for analogs. However, we envision that a future operational version of this system (WIND-2) will incorporate available prevision of attributes (e.g., imminent wind shifts or precipitation onsets predicted by other means) to guide its search for analogs.
65 Sivillo et al. (1997) define an ensemble forecast as: "a collection (an ensemble) of [numerical-weather-prediction-based] forecasts that all verify at the same time. These forecasts are regarded as possible scenarios given the uncertainty associated with forecasting." Ensembles are made by running competitive and/or slightly-differently-initialized numerical weather prediction models concurrently. Sivillo et al. (1997) explain how the average of an ensemble of forecasts tends to be more accurate than single-scenario forecasts.
66 To maximize reliability of forecasting and the probability of detection of an event, one simply needs to forecast the event to happen every time. The drawback with this strategy is that the false alarm ratio would rise at the same time. Forecasters refer to this strategy as "crying wolf." If one always raises an alarm, one will never miss an event, but one will also raise too many false alarms.
67 Conditional-persistence based forecasting is referred to in meteorology as "climatological persistence" (Vislocky and Fritsch 1997).
![]()
![]()
![]()